#statstab #515 Confounded dose-response effects of treatment adherence: fitting Bayesian instrumental variable models using brms
Thoughts: A nice tutorial on how to think about confounding, Simulating data, and making inferences
#statstab #515 Confounded dose-response effects of treatment adherence: fitting Bayesian instrumental variable models using brms
Thoughts: A nice tutorial on how to think about confounding, Simulating data, and making inferences
#statstab #509 Effective sample size
Thoughts: ESS often reported for bayesian models, but is it really understood?
#brms #rstats #r #bayesian #ess #diagnostics
https://statmodeling.stat.columbia.edu/2025/11/27/effective-sample-size/
#statstab #507 Nonlinear models in {flocker}
Thoughts: I'm thinking these are useful if my theory predicts some natural limit (L) for a process. Like memory recall.
#nonlinear #glmm #brms #mem #asymtotic #flocker #r #rstats
https://www.maths.bris.ac.uk/R/web/packages/flocker/vignettes/nonlinear_models.html
Compositional data (proportions that sum to 1) behave in ways standard models aren’t built for
I walk through why Dirichlet regression is often the right tool & what extra insight it gives, using a real example of eyetracking
#Dirichlet #r #brms #guide #eyetracking #ordbetareg #tutorial #reanalysis #substack
#statstab #477 Simulating data for Dirichlet regression with varying estimates
Thoughts: Interesting thread about an underused model.
#Dirichlet #brms #poweranalysis #rstats #proportions #stan #forum

Hello everyone, The shortest formulation of my problem is the following: I’m trying to design a power analysis by simulation for a Dirichlet regression model using brms. How could we calculate the shape parameter alpha of the Dirichlet distribution by hand from a theoretical model in order to feed it to brms::rdirichlet(n, alpha) to simulate data with chosen effects? The goal is to tweak manually the coefficients of the model to simulate data with varying effect sizes. Now for the lengthier c...
#statstab #466 Bayesian workflow: Prior determination, predictive checks and sensitivity analyses
Thoughts: Having a good bayesian work flow can be challenging with complex models.
#priors #bayesian #sensitivityanalysis #posterior #ppc #brms
#statstab #464 Plotting p-check interaction {brms}
Thoughts: Annoyingly #brms doesn't natively allow plotting for interactions (that I know of). The forum has a solution.
#ppc #posterior #bayesian #modelfit #diagnostic #rstats #r #stan
https://discourse.mc-stan.org/t/plotting-pp-check-interactions/31936

I am trying to model ordinal data with an interaction of two predictors. However, I have issues with plotting interactions and individual data with the BRMS functions. My model is of the type rating ~ category*distortion+ (1|id) I can use this type of code: pp_check(mcatxdistRDpCexp, type = “bars_grouped”, group = “category”, , ndraws = 500, prob = 0.95) pp_check(mcatxdistRDpCexp, type = “bars_grouped”, group = “distortion”, , ndraws = 500, prob = 0.95) which returns these two plots: ...
Rekomendasi Trading bulan ini adalah BRMS & PSAB kembali mencuri momentum seiring harga emas.
Mulai dari info insider trading dan perspektif investor.
Apakah Sentimen komoditas menguat, peluang masih terbuka?
Tetap perhatikan volatilitas pasar di Bareksa.
#Bareksa #TradingSaham #BRMS #PSAB #HargaEmas #GoldUpdate #SahamTambang #MarketToday
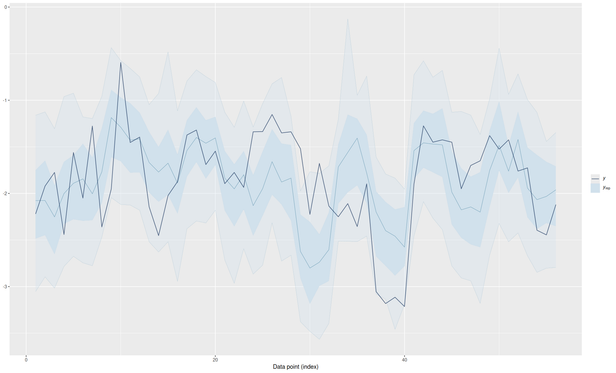
To the Bayesian pros: Is this is an OK-ish loo_ribbon plot?
Im using pp_check from #brms
Maybe @paul_buerkner could help 😅 ?
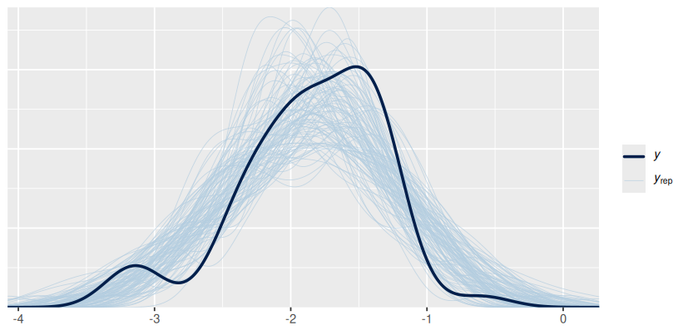
The ppd looks like this.
Im not super happy because that small bimodality is not well captured, but perhaps is too small and it doesnt matter?