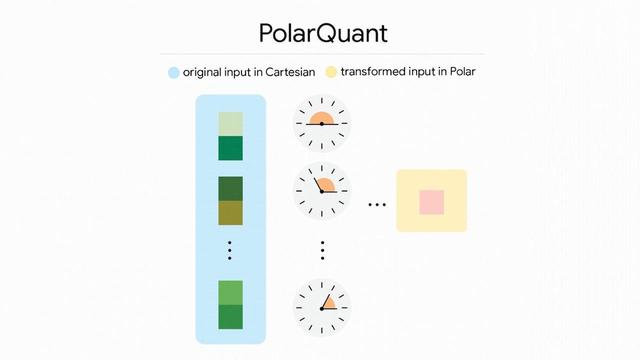
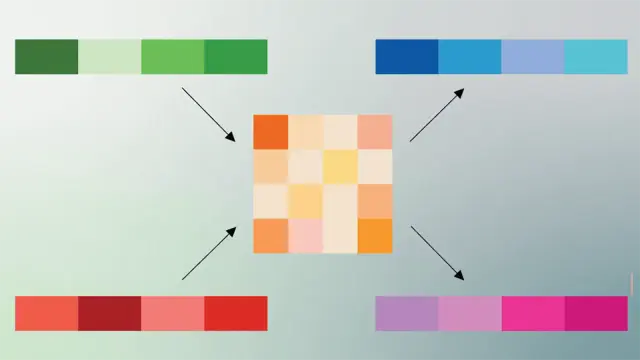
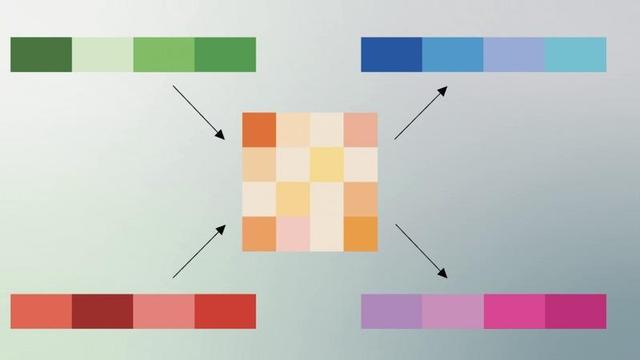
https://winbuzzer.com/2026/03/26/googles-turboquant-reduces-ai-llm-cache-memory-xcxwbn/
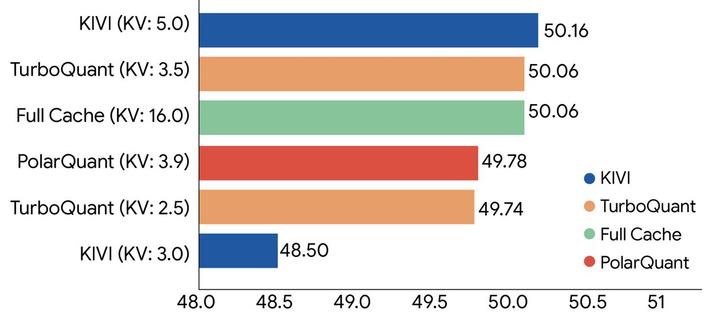
Google's TurboQuant Slashes LLM Memory Use by 6x
#AI #Google #Turboquant #Polarquant #LLMs #AIResearch #AIInference #GoogleAI #MachineLearning #DeepLearning #BigTech #DataCenters #CloudComputing #GoogleDeepMind