Chubby (@kimmonismus)
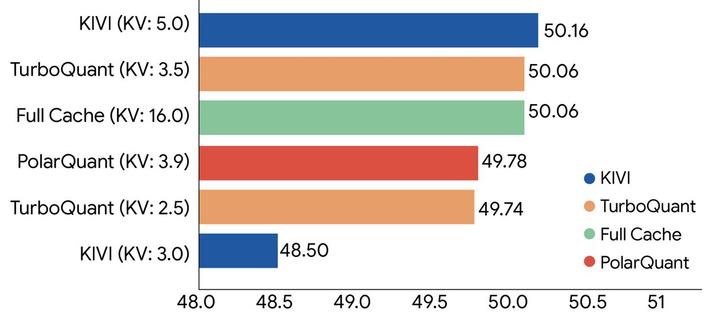
Google Research가 대형 언어모델의 메모리 사용량을 최소 6배 줄이는 압축 알고리즘 TurboQuant를 발표했다. 재학습 없이 정확도 손실도 없다고 하며, ICLR 2026에서 소개될 예정이다. LLM 배포 효율을 크게 높일 수 있는 주목할 만한 연구다.
Chubby♨️ (@kimmonismus) on X
Thats freaking awesome: Google Research has introduced TurboQuant, a compression algorithm (presenting at ICLR 2026) that shrinks the memory footprint of large language models by at least 6x, without any retraining or drop in accuracy. It works by converting data into a polar