🔍 Major breakthrough in multimodal AI research:
#InfinityMM dataset launches with 43.4M entries across 4 categories: 10M image descriptions, 24.4M visual instructions, 6M high-quality instructions & 3M #AI generated data
🧠 Technical highlights:
New #AquilaVL2B model uses #LLaVA architecture with #Qwen25 language model & #SigLIP for image processing
Despite only 2B parameters, achieves state-of-the-art results in multiple benchmarks
Exceptional performance: #MMStar (54.9%), #MathVista (59%), #MMBench (75.2%)
🚀 Training innovation:
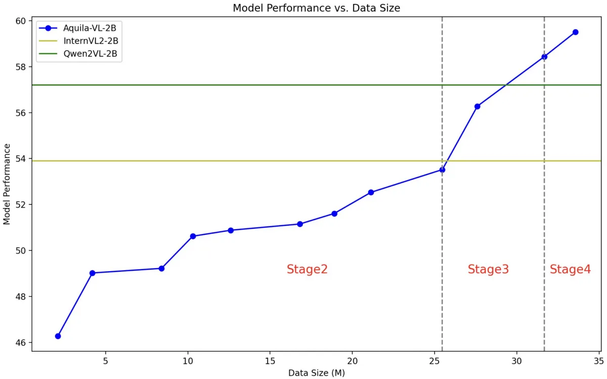
4-stage training process with increasing complexity
Combines image recognition, instruction classification & response generation
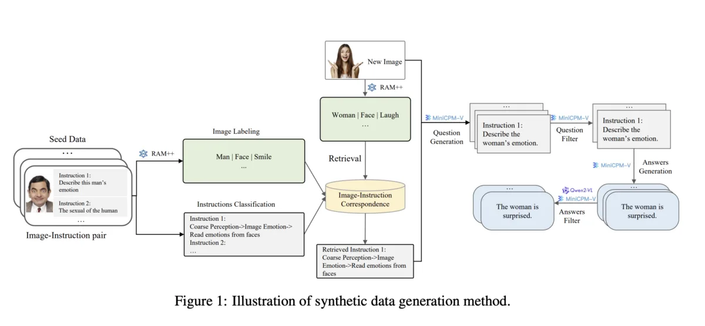
Uses #opensource models like RAM++ for data generation
💡 Industry impact:
Model trained on both #Nvidia A100 GPUs & Chinese chips
Complete dataset & model available to research community
Shows promising results compared to commercial systems like #GPT4V
https://arxiv.org/abs/2410.18558