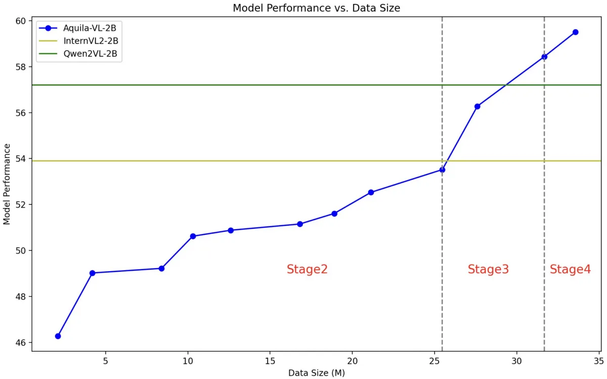
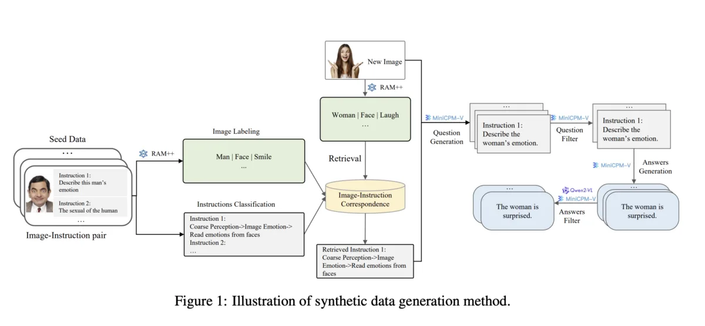
[Перевод] Картинка стоит 170 токенов: как GPT-4o кодирует изображения?
Интересный факт : GPT-4o взимает по 170 токенов за обработку каждого тайла 512x512 , используемого в режиме высокого разрешения. При соотношении примерно 0,75 токенов на слово можно предположить, что картинка стоит примерно 227 слов, что всего в четыре раза меньше, чем в поговорке «картинка стоит тысячи слов». (Кроме того, взимается 85 токенов за master thumbnail низкого разрешения каждого изображения, а изображения более высокого разрешения разбиваются на множество таких тайлов 512x512 , но давайте ограничимся одним тайлом высокого разрешения.) Но почему же 170? Необычное число, неправда ли? В своих ценах OpenAI указывает округлённые числа, например, $20 или $0,50, а в своих внутренних размерностях — степени двойки и тройки. Почему же в этом случае выбрано число 170? Числа, которые без объяснений вставляют в кодовую базу, называют в программировании « магическими числами », и 170 кажется очевидным магическим числом. И почему затраты на изображения вообще преобразуются в стоимость в токенах? Если бы это нужно было только для определения цены, то разве не удобнее было бы просто указать цену за тайл? Что, если OpenAI выбрала 170 не в рамках своей запутанной стратегии ценообразования, а потому что это в буквальном смысле так? Что, если тайлы изображений действительно представлены в виде 170 последовательных векторов эмбеддингов? А если это так, то как реализовано?
https://habr.com/ru/articles/834548/
#openai #gpt4 #gpt4o #gpt4v #эмбеддинги