🔍 Major breakthrough in multimodal AI research:
#InfinityMM dataset launches with 43.4M entries across 4 categories: 10M image descriptions, 24.4M visual instructions, 6M high-quality instructions & 3M #AI generated data
🧠 Technical highlights:
New #AquilaVL2B model uses #LLaVA architecture with #Qwen25 language model & #SigLIP for image processing
Despite only 2B parameters, achieves state-of-the-art results in multiple benchmarks
Exceptional performance: #MMStar (54.9%), #MathVista (59%), #MMBench (75.2%)
🚀 Training innovation:
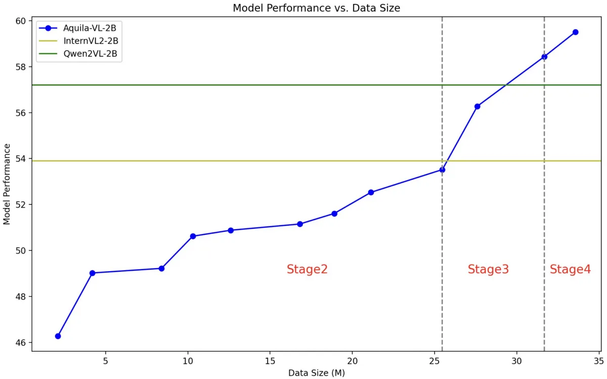
4-stage training process with increasing complexity
Combines image recognition, instruction classification & response generation
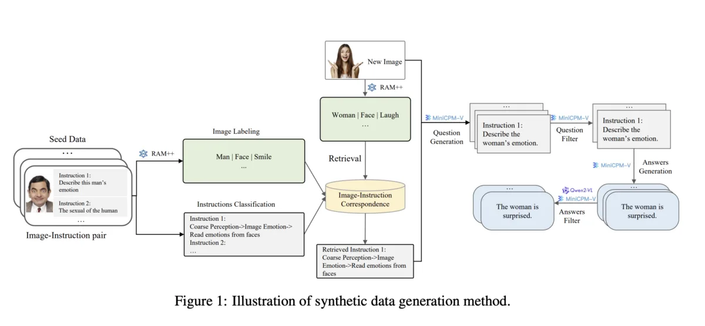
Uses #opensource models like RAM++ for data generation
💡 Industry impact:
Model trained on both #Nvidia A100 GPUs & Chinese chips
Complete dataset & model available to research community
Shows promising results compared to commercial systems like #GPT4V

Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Recently, Vision-Language Models (VLMs) have achieved remarkable progress in multimodal tasks, and multimodal instruction data serves as the foundation for enhancing VLM capabilities. Despite the availability of several open-source multimodal datasets, limitations in the scale and quality of open-source instruction data hinder the performance of VLMs trained on these datasets, leading to a significant gap compared to models trained on closed-source data. To address this challenge, we introduce Infinity-MM, a large-scale multimodal instruction dataset. We collected the available multimodal instruction datasets and performed unified preprocessing, resulting in a dataset with over 40 million samples that ensures diversity and accuracy. Furthermore, to enable large-scale expansion of instruction data and support the continuous acquisition of high-quality data, we propose a synthetic instruction generation method based on a tagging system and open-source VLMs. By establishing correspondences between different types of images and associated instruction types, this method can provide essential guidance during data synthesis. Leveraging this high-quality data, we have trained a 2-billion-parameter Vision-Language Model, Aquila-VL-2B, which achieves state-of-the-art (SOTA) performance among models of similar scale. The data is available at: https://huggingface.co/datasets/BAAI/Infinity-MM.
