🔍 Spark + Elasticsearch Debugging 🧵
Building a cybersecurity analytics platform. Hit 2 blockers:
❌ JAR path mismatch → Fixed absolute path
❌ No data nodes (single-node Docker ES) → Added es.nodes.wan.only=true
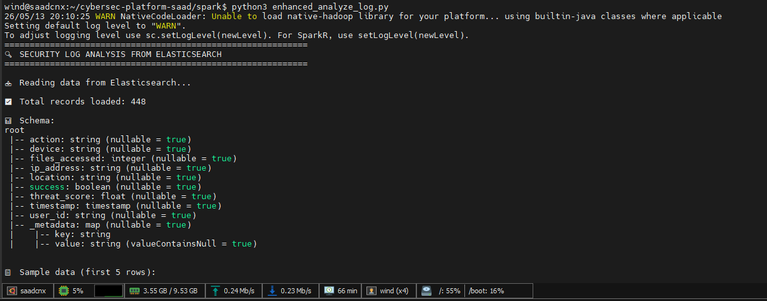
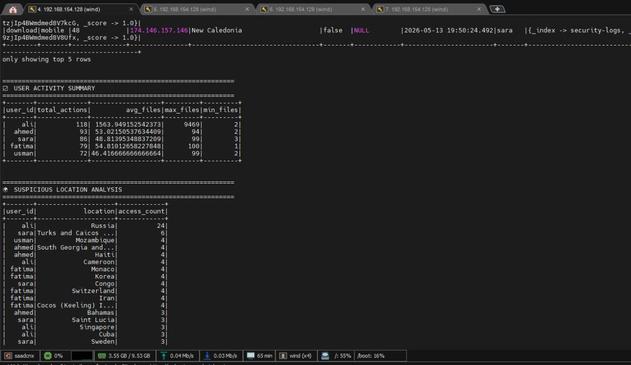
✅ Result: 89 records loaded. Working pipeline!
Lesson: Verify JAR paths + disable node discovery for single-node ES.
#PySpark #Elasticsearch #DataEngineering #CyberSecurity #Debugging