RE: https://vivoweb.org/2026/03/03/request-for-comments-disambiguation-deduplication-spec/
A #disambiguation and #deduplication engine for #VIVO will be developed. The proposed specs are published now, they are open for comments until March 17.
RE: https://vivoweb.org/2026/03/03/request-for-comments-disambiguation-deduplication-spec/
A #disambiguation and #deduplication engine for #VIVO will be developed. The proposed specs are published now, they are open for comments until March 17.
Databricks just showed that clean, deduped data beats fancy model tweaks for faster LLMs. Their paper reveals a simple data pipeline—language filtering, deduplication, and high‑quality datasets—outperforms architecture tweaks on GPU training. Curious how to boost speed without extra compute? Dive in. #LLMTraining #DataQuality #Databricks #Deduplication
🔗 https://aidailypost.com/news/databricks-paper-finds-data-quality-outweighs-model-architecture-llm

Fixing Noisy Logs with #OpenTelemetry Log #Deduplication
https://www.dash0.com/guides/opentelemetry-log-deduplication-processor
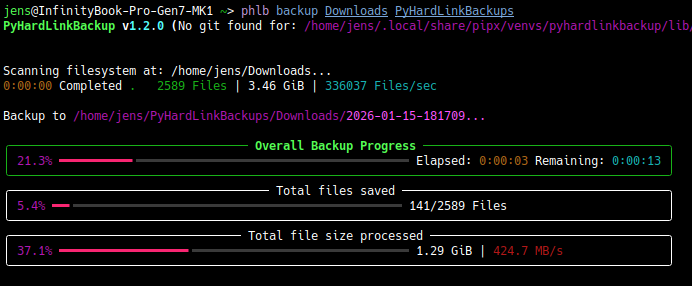
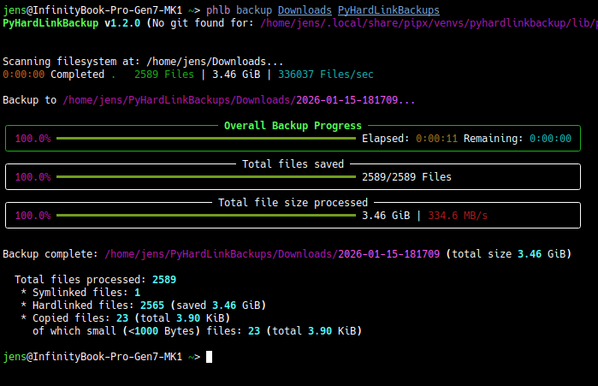
Hab mein PyHardLinkBackup komplett neu geschrieben. Ursprünglich 2015 gestartet und bis 2020 genutzt, schlief es jetzt fast 6 Jahre...
Aber als ich über alte damit erstellte backups gestolpert bin, hab ich mir gedacht, das Konzept ist doch ganz nützlich.
Also kompletter rewrite: https://github.com/jedie/PyHardLinkBackup
And once in a while I cleanup the external libraries with #Czkawka
This is an amazing software for #deduplication of image folders.
Sick: Indexed deduplicated binary storage for JSON-like data structures
#HackerNews #Sick #Indexed #Binary #Storage #JSON #Deduplication #DataStructures
The machine forgets. The Ghost does not.
https://deadswitch.tomsitcafe.com/2025/10/borg-backup-intro.html
Part 1 : #PySpark Data Pre-processing Essentials #filtering || #Deduplication || Data Cleansing.
Learn PySpark data pre-processing with our tutorial! Learn the art of filtering and deduplication, essential techniques for cleaning ... source
Ich hab mal versucht, die Speicheroptimierung durch #Deduplication beim #Backup mit #restic zu quantifizieren. Dies nach einer Laufzeit von knapp 2 Jahren.
Herausgekommen ist: 22,4%
# restic stats latest
repository d989459c opened successfully, password is correct
scanning...
Stats in restore-size mode:
Snapshots processed: 1
Total File Count: 438037
Total Size: 23.271 GiB
# restic stats latest --mode raw-data
repository d989459c opened successfully, password is correct
scanning...
Stats in raw-data mode:
Snapshots processed: 1
Total Blob Count: 265960
Total Size: 18.409 GiBHoffe, das richtig interpretiert zu haben.




