
Как выбрать лучшего AI-ассистента для разработки: тестируем Codex, Claude и Cursor
В 2026 году кодовые ассистенты окончательно перестали быть просто автокомплитом и превратились в полноценный инструмент разработки: они читают кодовую базу целиком, понимают зависимости, дебажат по логам и могут довести задачу до рабочего состояния почти без участия разработчика. Но на практике всё не так однозначно — один агент хорошо чинит баги, но ломает архитектуру, другой уверенно пишет на Python, но теряется в TypeScript. Чтобы разобраться, кто из них реально помогает в разработке, а кто только выглядит убедительно, мы прогнали популярные решения через собственный приватный бенчмарк с задачами на 15+ языках. Меня зовут Ильнур Файзиев, я руковожу юнитом Data LLM в
https://habr.com/ru/companies/doubletapp/articles/1014646/
#codex #cursor #claude_code #swebench #ai #aiассистент #ai_agent #gpt53_codex #opus #sonnet

Awni Hannun (@awnihannun)
최전선 AI 모델의 성능이 3년 전과 비교해 놀라울 정도로 향상됐다고 평가하며, Opus 4.6과 GPT 5.4 같은 모델을 예로 든다. AGI나 급격한 자기개선 여부와 무관하게 현재 모델의 능력이 매우 인상적이라는 내용이다.

🤣 Oh look, it's 2026, and we're having another #déjà #vu with #OpenClaw, the latest "promising" security disaster masquerading as innovation! Apparently, this time, it's powered by #Opus, because clearly nothing screams progress like polishing a three-year-old #AI toy and pretending it's new. 🧠💥
https://composio.dev/content/openclaw-security-and-vulnerabilities #SecurityDisaster #Innovation #HackerNews #ngated
https://composio.dev/content/openclaw-security-and-vulnerabilities #SecurityDisaster #Innovation #HackerNews #ngated

Das chinesische #llm #MiniMax M2.7 übertrifft seinen Vorgänger M2.5 bei weitem und ist im Bereich von Athropics #Opus angekommen.
Leider scheint sich nun auch die Veröffentlichungsstrategie von #OpenWeight zu propritär zu wandeln.
Ich bin gespannt wie sich die chinesische Konkurrenz #Kimi, #GLM und #Qwen in Zukunft verhält.
Ich halte OpenWeight für unverzichtbar - der Markt vielleicht schon.
Leider scheint sich nun auch die Veröffentlichungsstrategie von #OpenWeight zu propritär zu wandeln.
Ich bin gespannt wie sich die chinesische Konkurrenz #Kimi, #GLM und #Qwen in Zukunft verhält.
Ich halte OpenWeight für unverzichtbar - der Markt vielleicht schon.
looking up modern free audio codecs i come across both #Opus and LC3 (from LE Audio)
both are described as efficient, low latency, with good quality
everything online talks like they are in unrelated category's
Opus has a bluetooth profile (used in one device.) How would LC3 compare if i stored my files in it?
i think the wireless case is really interesting because complexity and bitrate both effectively translate to power consumption, but the balance between them depends on hardware
It seems I've run into this weird EastWest Opus cut-off bug, where it just decides to not sustain all the notes I play. It's reported at https://vi-control.net/community/threads/eastwest-hoopus-notes-cut-off.128457/ and none of the suggested fixes fix it. Super annoying and quite disappointing of such an expensive piece of software.
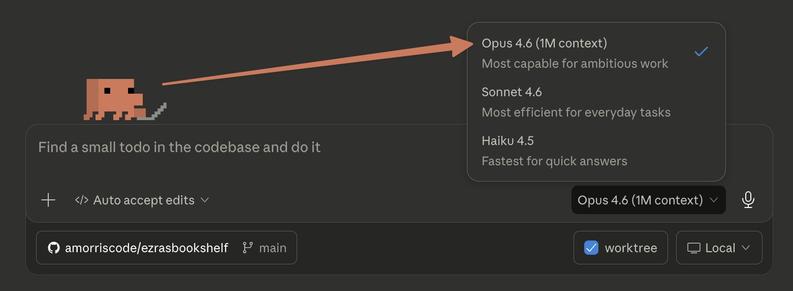
Anthony Morris ツ (@amorriscode)
Opus 4.6 버전이 데스크톱의 Max/Teams/Enterprise 요금제에 대해 1M(100만) 문맥(context) 지원으로 출시되었다는 공지로, 매우 큰 문맥 창을 제공하는 업데이트임을 알림.
Wes Roth (@WesRoth)
동일한 딥리서치 프롬프트를 GPT 5.4, Opus 5.6, Gemini Deep Research(추정 Gemini 3.0)에 걸쳐 비교 실행(대부분 약 30분 소요). 작성자는 GPT 5.4가 매우 '반사적으로 반대 의견'을 보이며, 사용자의 사고에서 잘못된 점을 지적하는 데 우선순위를 두는 성향이 있어 불편하다고 평가함.

Wes Roth (@WesRoth) on X
I've ran the same prompt for deep research through GPT 5.4, Opus 5.6 and Gemini Deep Research (I assume Gemini 3.0) most of them ran for ~30 mins GPT 5.4 is *REALLY* annoying! it's "reflexively contrarian", it prioritizes showing you what's wrong with your thinking, NOT