Real-Time Vision Models
Discover how YOLO26 achieves real-time vision, transforming industries like security and healthcare

Real-Time Vision Models
Discover how YOLO26 achieves real-time vision, transforming industries like security and healthcare
An Introduction to YOLO26
https://blog.roboflow.com/yolo26/
#HackerNews #YOLO26 #computervision #deeplearning #objectdetection #Roboflow #AI
Build a Live Object Detection App for the Reachy Mini With TensorFlow and PyCharm
#Pycharm #Datascience #Tutorials #Computervision #Objectdetection #Python #Tensorflow
Title: P3: preparing for interview and reading paper [2024-02-28 Wed]
detection networks. It uses predefined anchor boxes and their
pyramides. There is a sliding window, a box-regression layer
(reg) and a box-classification layer (cls).
Anchor-free object detection methods is CenterNet, FCOS
(Fully Convolutional One-Stage Object Detection) and
DETR (DEtection TRansformers)
😶 #dailyreport #cv #objectdetection #fsl #deeplearning
Title: P2: preparing for interview and reading paper [2024-02-28 Wed]
- Learn-to-Parameterize - param eterizing the base learner or
some subparts of base learner for a novel task so that it can
address this task specifically. meta learner generate weights
for base learner.
- Learn-to-Adjust
- Learn-to-Remember
Also this article have good overview of all ML tasks.
Region Proposal Network (RPN) is a backbone of first object #dailyreport #cv #objectdetection #fsl #deeplearning
Title: P0: preparing for interview and reading paper [2024-02-28 Wed]
Few shot learning (FSL):
- 2023 A Survey on Machine Learning from Few Samples
CV Object detecttion:
- 2016 Faster R-CNN: Towards Real-Time Object
Detection with Region Proposal Networks
- 2018 Mask R-CNN
- 2015 YOLO
Most solutions for FSL in non-deep period before 2015
was generative based, but then discriminative.
Discriminative approaches is: #dailyreport #cv #objectdetection #fsl #deeplearning
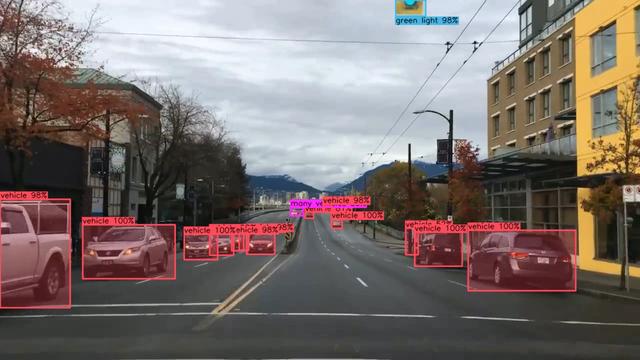
Talk on the discord about how much time it takes to process images with Darknet/YOLO. No need to guess and throw wild speculation -- run any of the built-in Darknet/YOLO tools and it will tell you exactly how long it takes at every step.
loading /home/stephane/nn/driving/set_04_dash/frame_064661.jpg
-> reading image from disk ........... 3.781 milliseconds [1280 x 720 x 3] [78.7 KiB]
-> resizing image to network dims .... 0.383 milliseconds [640 x 352 x 3]
-> using Darknet to predict .......... 2.581 milliseconds [7 objects]
-> using Darknet to annotate image ... 0.071 milliseconds [1280 x 720 x 3]
-> save output image to disk ......... 2.123 milliseconds [84.9 KiB]
-> total time elapsed ................ 9.324 milliseconds [107 FPS]
Train Custom Deep Learning Models Without Coding using QGIS, Roboflow and Ultralytics
I don't talk about Darknet/YOLO much anymore on Mastodon. But I maintain the modern Darknet/YOLO repo.
This repo, written in C++ and CUDA, is used to analyze images and video frames to find objects. You train a neural network to identify things you need, and then you give it images or videos to inspect.
Darknet/YOLO is completely free. Uses the Apache 2 license.
The GitHub mirror is here: https://github.com/hank-ai/darknet/tree/v6-dev#table-of-contents
The main repo is here: https://codeberg.org/CCodeRun/darknet/src/branch/v6-dev#table-of-contents
An example image:
#Darknet #YOLO #NeuralNetwork #ObjectDetection