От вет-ИИ для коров до имперского глянца: хардкорный MLOps на бесплатных GPU
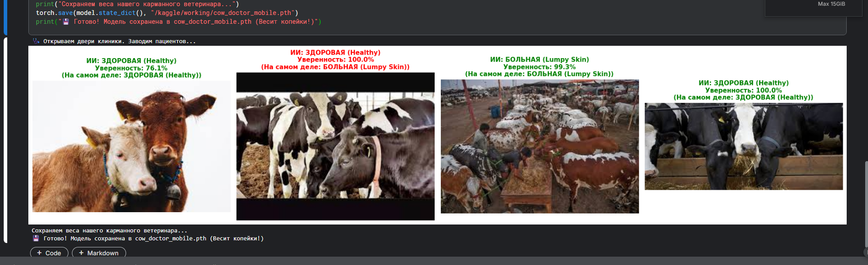
В начале 2026 года ленты новостей принесли тревожные сообщения из Сибири: массовые вспышки опасных заболеваний у КРС (крупного рогатого скота) привели к необходимости вынужденного забоя тысяч голов. Для многих фермеров это означало потерю бизнеса и средств к существованию. Мы задались вопросом: может ли доступный Computer Vision стать первой линией обороны? Инструментом, который позволит фермеру в отдаленном районе провести первичный скрининг (триаж) животного с помощью обычного смартфона и вовремя вызвать ветеринара, не дожидаясь начала эпидемии. Так родился проект AI-Vet-Scanner ( наше пространство на Hugging Face ), определяющий признаки заболеваний по фотографии.
https://habr.com/ru/articles/1013214/
#MLOps #Kaggle #Computer_Vision #OpenCV #PyMuPDF #Hugging_Face #датасет #парсинг #оптимизация_памяти #SDXL_LoRA