Using #Atari8Bit based #SynapseSoftware #SynCalc to compare #GeekBench values and decide on Apple #MacBookPro #M1Max 10/32 upgrade path. M4 Max seems to be the only viable path.
The A8 posed a bit of struggle with limited screen space.
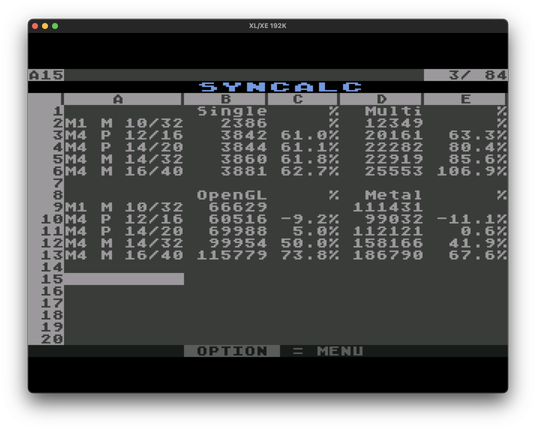
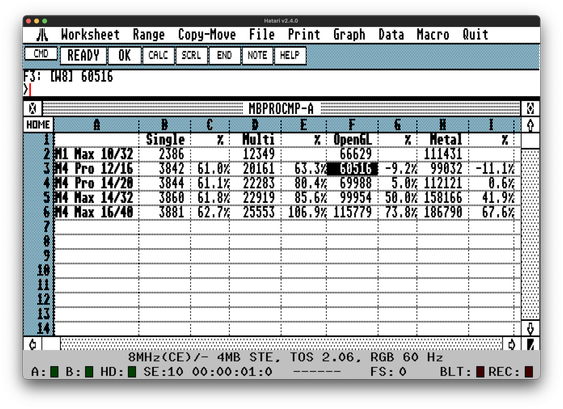
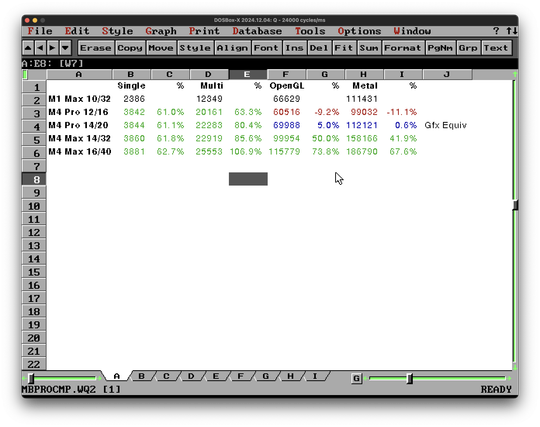
Using #Atari8Bit based #SynapseSoftware #SynCalc to compare #GeekBench values and decide on Apple #MacBookPro #M1Max 10/32 upgrade path. M4 Max seems to be the only viable path.
The A8 posed a bit of struggle with limited screen space.

Les MacBook Pro M1 Max de 16" sont arrivés livrés avec un mode Performance permettant d’optimiser la puissance pour les charges de travail intensives et prolongées. Si ce mode a pendant un temps été réservé aux machines très haut de gamme (puces Max ...



