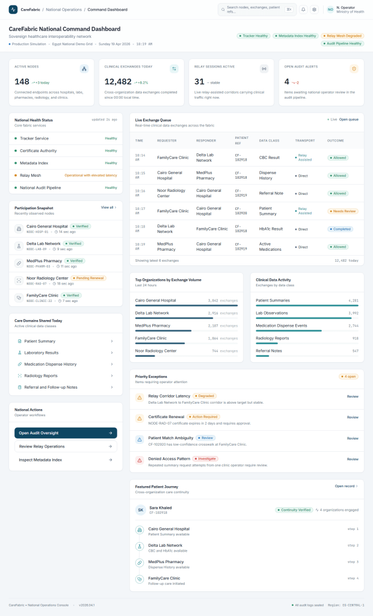
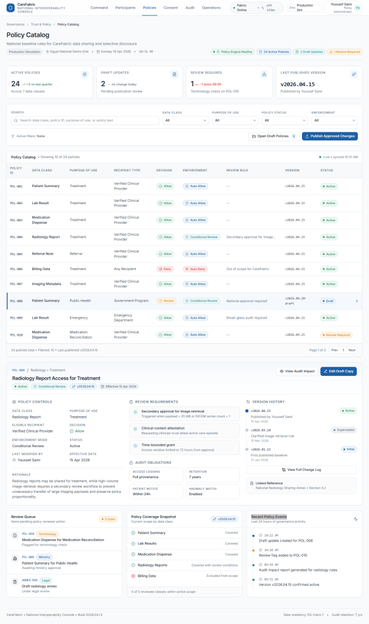
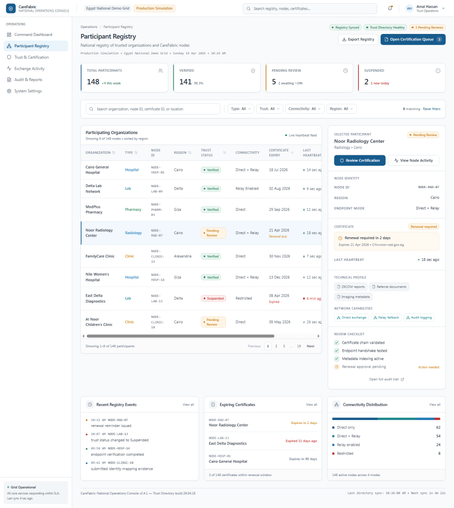
Federated Learning Spreads the Training. It Does Not Spread the Trust.
Federated learning distributes where training happens, and people quietly assume it distributes trust along with it. It does not. You can decentralise the computation completely and still be unable to prove what the system actually did. The fix is not more decentralisation. It is one signed, offline-verifiable record that…
https://mickai.co.uk/articles/federated-learning-needs-a-sovereign-anchor
#federatedlearning #AIgovernance #sovereignAI #auditability #postquantum

Federated Learning Spreads the Training. It Does Not Spread the Trust.
Federated learning distributes where training happens, and people quietly assume it distributes trust along with it. It does not. You can decentralise the computation completely and still be unable to prove what the system actually did. The fix is not more decentralisation. It is one signed, offline-verifiable record that no participant can rewrite.