
| Blog | https://www.omarpolo.com/ |
| Italian Blog | https://it.omarpolo.com |
| Gemini Capsule | gemini://gemini.omarpolo.com |
| Honk | @[email protected] |

| Blog | https://www.omarpolo.com/ |
| Italian Blog | https://it.omarpolo.com |
| Gemini Capsule | gemini://gemini.omarpolo.com |
| Honk | @[email protected] |
hahaa! Successfully removed all IR and UV filters from my old Canon EOS 600D, I can do full spectrum, UV and IR photography now!
All of the following photos have been taken with a ~550nm+ lpf, meaning cutting everything under 550nm (blue, purple and uv) off. I love the vibrant pink foliage and dramatic turquoise skies #photography



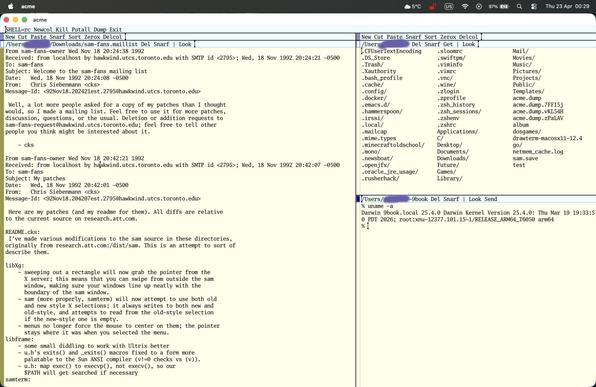
so i have been learning #sam and #acme properly and oh my god. acme is the best editor i have ever used. i love the fact that it really is an os interface in its own right. i have been completely underutilising it. i now have a setup on my second desktop at all times.
sam just seems like ed on steroids with a lot of the acme benefits of the mouse interface.
i am using acme for actual work or writing and i use sam for quick edits or config files.
@frederic Yes. People who couldn't be arsed to write a single word of documentation for their human colleagues suddenly don't have any issue at all with writing miles and miles of instructions for their AI colleagues.
Same for people who previously couldn't find time to mentor a student or new junior colleague because "it's too much work to describe the task in enough detail". For their LLM? No problem at all. 🤷
That's the one that really gets under my skin.
I’ve heard this argument before and I disagree with it. My goal for Free Software is to enable users, but that requires users have agency. Users being able to modify code to do what they want? Great! Users being given a black box that will modify their code in a way that might do what they want but will fail in unpredictable ways, without giving them any mechanism to build a mental model of those failure modes? Terrible!
I am not a carpenter but I have an electric screwdriver. It’s great. It lets me turn screws with much less effort than a manual one. There are a bunch of places where it doesn’t work, but that’s fine, I can understand those and use the harder-to-use tool in places where it won’t work. I can build a mental model of when not to use it and why it doesn’t work and how it will fail. I love building the software equivalent of this, things that let end users change code in ways I didn’t anticipate.
But LLM coding is not like this. It’s like a nail gun that has a 1% chance of firing backwards. 99% of the time, it’s much easier than using a hammer. 1% of the time you lose an eye. And you have no way of knowing which it will be. The same prompt, given to the same model, two days in a row, may give you a program that does what you want one time and a program that looks like it does what you want but silently corrupts your data the next time.
That’s not empowering users, that’s removing agency from users. Tools that empower users are ones that make it easy for users to build a (nicely abstracted, ignoring details that are irrelevant to them) mental model of how the system works and therefor the ability to change it in precise ways. Tools that remove agency from users take their ability to reason about how systems work and how to effect precise change.
I have zero interest in enabling tools that remove agency from users.
Software Heritage recrute :
• Ingénieur.e Back-end
• Ingénieur·e DevOps
• Responsable Applications Internes (Odoo/IT)
Détails des postes : https://www.softwareheritage.org/jobs/?lang=fr

Good morning!
The last episode of the #OpenBSD on m88k story has been released: http://miod.online.fr/software/openbsd/stories/m88k5.html
You can also read the whole story on a single page:
http://miod.online.fr/software/openbsd/stories/m88kall.html
Stay tuned for a new story next week!
A few notes about the massive hype surrounding Claude Mythos:
The old hype strategy of 'we made a thing and it's too dangerous to release' has been done since GPT-2. Anyone who still falls for it should not be trusted to have sensible opinions on any subject.
Even their public (cherry picked to look impressive) numbers for the cost per vulnerability are high. The problem with static analysis of any kind is that the false positive rates are high. Dynamic analysis can be sound but not complete, static analysis can be complete but not sound. That's the tradeoff. Coverity is free for open source projects and finds large numbers of things that might be bugs, including a lot that really are. Very few projects have the resources to triage all of these. If the money spent on Mythos had been invested in triaging the reports from existing tools, it would have done a lot more good for the ecosystem.
I recently received a 'comprehensive code audit' on one of my projects from an Anthropic user. Of the top ten bugs it reported, only one was important to fix (and should have been caught in code review, but was 15-year-old code from back when I was the only contributor and so there was no code review). Of the rest, a small number were technically bugs but were almost impossible to trigger (even deliberately). Half were false positives and two were not bugs and came with proposed 'fixes' that would have introduced performance regressions on performance-critical paths. But all of them looked plausible. And, unless you understood the environment in which the code runs and the things for which it's optimised very well, I can well imaging you'd just deploy those 'fixes' and wonder why performance was worse. Possibly Mythos is orders of magnitude better, but I doubt it.
This mirrors what we've seen with the public Mythos disclosures. One, for example, was complaining about a missing bounds check, yet every caller of the function did the bounds check and so introducing it just cost performance and didn't fix a bug. And, once again, remember that this is from the cherry-picked list that Anthropic chose to make their tool look good.
I don't doubt that LLMs can find some bugs other tools don't find, but that isn't new in the industry. Coverity, when it launched, found a lot of bugs nothing else found. When fuzzing became cheap and easy, it found a load of bugs. Valgrind and address sanitiser both caused spikes in bug discovery when they were released and deployed for the first time.
The one thing where Mythos is better than existing static analysers is that it can (if you burn enough money) generate test cases that trigger the bug. This is possible and cheaper with guided fuzzing but no one does it because burning 10% of the money that Mythos would cost is too expensive for most projects.
The source code for Claude Code was leaked a couple of weeks ago. It is staggeringly bad. I have never seen such low-quality code in production before. It contained things I'd have failed a first-year undergrad for writing. And, apparently, most of this is written with Claude Code itself.
But the most relevant part is that it contained three critical command-injection vulnerabilities.
These are the kind of things that static analysis should be catching. And, apparently at least one of the following is true:
TL;DR: If you're willing to spend half as much money Mythos costs to operate, you can probably do a lot better with existing tools.
Anthropic's Claude Code CLI contains three critical command injection vulnerabilities that allow attackers to execute arbitrary code and exfiltrate cloud credentials via environment variables, file paths, and authentication helpers. These flaws bypass the tool's internal sandbox and are particularly dangerous in CI/CD environments where trust dialogs are disabled.
