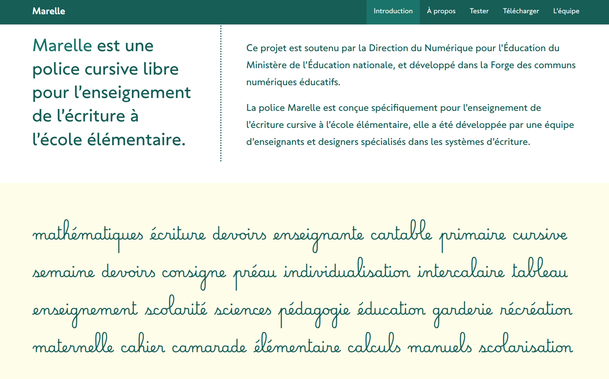
🇺🇦
🇺🇦I'm leaving #Google: https://www.mayrhofer.eu.org/post/leaving-google/
While I believe that I have been able to do some good with my continuing (part-time) engagement in the Android security and privacy team since returning to Austria a couple of years ago, the deal with the US #DoW is completely misaligned with my personal ethical principles. I will, therefore, no longer be able to act as a contact point to Google-internal teams and discussions, but will continue our research on private digital identity, end-to-end secure communication and storage, network privacy, (embedded/mobile) operating system security, supply chain transparency, etc. from a purely academic point of view. Android - and in particular AOSP - will remain a research interest, so please feel free to reach out on any of those topics for potential collaborations or discussions on the academic side.