Today's threads (a thread)
Inside: The web is bearable with RSS; and more!
Archived at: https://pluralistic.net/2026/03/07/reader-mode/
1/
Today's threads (a thread)
Inside: The web is bearable with RSS; and more!
Archived at: https://pluralistic.net/2026/03/07/reader-mode/
1/
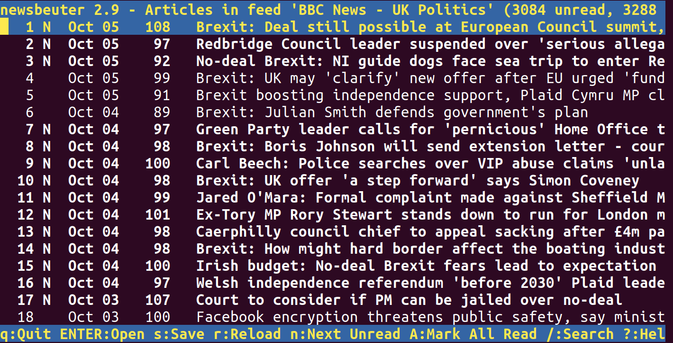
The web is bearable with RSS: And don't forget "Reader Mode."
https://mamot.fr/@pluralistic/116189252557112667
2/

Hey look at this
* The Real Litmus Test for Democratic Presidential Candidates https://www.hamiltonnolan.com/p/the-real-litmus-test-for-democratic
* Users fume over Outlook.com email 'carnage' https://www.theregister.com/2026/03/04/users_fume_at_outlookcom_email/ (if you're on Outlook or Hotmail and haven't been getting my newsletter, this is why)
* You Bought Zuck’s Ray-Bans. Now Someone in Nairobi Is Watching You Poop. https://blog.adafruit.com/2026/03/04/you-bought-zucks-ray-bans-now-someone-in-nairobi-is-watching-you-poop/
* Indefinite Book Club Hiatus https://whatever.scalzi.com/2026/03/03/indefinite-book-club-hiatus/
* Art Bits from HyperCard https://archives.somnolescent.net/web/mari_v2/junk/hypercard/
3/

#25yrsago 200 Eyemodule photos from Disneyland https://craphound.com/030401/
#20yrsago Fourth Amendment luggage tape https://ideas.4brad.com/node/367
#15yrsago Glenn Beck’s syndicator runs a astroturf-on-demand call-in service for radio programs https://web.archive.org/web/20110216081007/http://www.tabletmag.com/life-and-religion/58759/radio-daze/
#15yrsago 20 lies from Scott Walker https://web.archive.org/web/20110308062319/https://filterednews.wordpress.com/2011/03/05/20-lies-and-counting-told-by-gov-walker/
#10yrsago The correlates of Trumpism: early mortality, lack of education, unemployment, offshored jobs https://web.archive.org/web/20160415000000*/https://www.washingtonpost.com/news/wonk/wp/2016/03/04/death-predicts-whether-people-vote-for-donald-trump/
4/

#10yrsago Hacking a phone’s fingerprint sensor in 15 mins with $500 worth of inkjet printer and conductive ink https://web.archive.org/web/20160306194138/http://www.cse.msu.edu/rgroups/biometrics/Publications/Fingerprint/CaoJain_HackingMobilePhonesUsing2DPrintedFingerprint_MSU-CSE-16-2.pdf
#10yrsago Despite media consensus, Bernie Sanders is raising more money, from more people, than any candidate, ever https://web.archive.org/web/20160306110848/https://www.washingtonpost.com/politics/sanders-keeps-raising-money--and-spending-it-a-potential-problem-for-clinton/2016/03/05/a8d6d43c-e2eb-11e5-8d98-4b3d9215ade1_story.html
#10yrsago Calculating US police killings using methodologies from war-crimes trials https://granta.com/violence-in-blue/
#1yrago Brother makes a demon-haunted printer https://pluralistic.net/2025/03/05/printers-devil/#show-me-the-incentives-i-will-show-you-the-outcome
5/

#1yrago Two weak spots in Big Tech economics https://pluralistic.net/2025/03/06/privacy-last/#exceptionally-american
6/

Thursday's threads: Blowtorching the frog; and more!
https://mamot.fr/@pluralistic/116178392047790544
7/

My latest novel is "Picks and Shovels," a historical technothriller set in the Weird Era of the PC, about Ponzi schemes, techbros, and the dawn of enshittification:
https://us.macmillan.com/books/9781250865908/picksandshovels
--
My latest nonfiction book is the internationally bestselling "Enshittification: Why Everything Suddenly Got Worse and What to Do About It," from MCD/Farrar, Straus and Giroux:
https://us.macmillan.com/books/9780374619329/enshittification/
8/
My ebooks and audiobooks (from FSGxMCD, Tor Books, Head of Zeus, McSweeneys, Beacon, Verso and others) are for sale all over the net, but I sell 'em too, and when you buy 'em from me, I earn twice as much and you get books with no DRM and no license "agreements."
9/

Upcoming appearances:
* #SanFrancisco: Launch for Cindy Cohn's "Privacy's Defender" (City Lights), Mar 10
https://citylights.com/events/cindy-cohn-launch-party-for-privacys-defender/
* #Barcelona: Enshittification with Simona Levi/Xnet (Llibreria Finestres), Mar 20
https://www.llibreriafinestres.com/evento/cory-doctorow/
* #Berkeley: Bioneers keynote, Mar 27
https://conference.bioneers.org/
* #Montreal: Bronfman Lecture (McGill) Apr 10
https://www.eventbrite.ca/e/artificial-intelligence-the-ultimate-disrupter-tickets-1982706623885
11/

Upcoming appearances (cont'd):
* #London: Resisting Big Tech Empires (LSBU)
https://www.tickettailor.com/events/globaljusticenow/2042691
* #Berlin: Re:publica, May 18-20
https://re-publica.com/de/news/rp26-sprecher-cory-doctorow
* #Berlin: Enshittification at Otherland Books, May 19
https://www.otherland-berlin.de/de/event-details/cory-doctorow.html
* #HayOnWye: HowTheLightGetsIn, May 22-25
https://howthelightgetsin.org/festivals/hay/big-ideas-2
12/

Recent appearances:
* The Virtual Jewel Box (U Utah)
https://tanner.utah.edu/podcast/enshittification-cory-doctorow-matthew-potolsky/
* Tanner Humanities Lecture (U Utah)
https://www.youtube.com/watch?v=i6Yf1nSyekI
* The Lost Cause
https://streets.mn/2026/03/02/book-club-the-lost-cause/
* Should Democrats Make A Nuremberg Caucus? (Make It Make Sense)
https://www.youtube.com/watch?v=MWxKrnNfrlo
* Making The Internet Suck Less (Thinking With Mitch Joel)
https://www.sixpixels.com/podcast/archives/making-the-internet-suck-less-with-cory-doctorow-twmj-1024/
14/

You can follow these posts as a daily blog at pluralistic.net: no ads, trackers, or data-collection!
Here's today's edition: https://pluralistic.net/2026/03/07/reader-mode/
--
If you prefer a newsletter, subscribe to the plura-list, which is ad-/tracker-free, and is utterly unadorned save a single daily emoji. Today's is "🦜". Suggestions solicited for future emojis!
--
You can also get a fulltext RSS feed, licensed CC BY 4.0:
15/
I'm also on Bluesky. Read today's thread there at:
https://bsky.app/profile/did:web:pluralistic.net/post/3mgigz5pw622l
eof/
@pluralistic These are great recommendations, and I can't wait to try them!
It's interesting how, as web search fails, word of mouth has been taking its place. In that spirit, I'd like to add that I use uBlock Origin rules to block parts of specific websites that I don't like. For example, these two custom rules will banish the New York Times Opinion section:
www.nytimes.com##div.css-1w1paqe:has(section#large-opinion-label)
www.nytimes.com##li[data-testid="nav-item-Opinion"]
using self-hosted selfoss for.. I dont know, whenever goole reader was killed.
@mpaluchowski @pluralistic : this approach is automatized and crowdsourced to extract the real content from enhshitified webpages.
ftr-site-config is a communautary project to create xpath rules for websites (more than 2000 websites supported currently)
unmerdify is a python library using those rules to parse a webpage.
#Offpunk is a command-line browser using unmerdify by default when available to read a website.
Say goodbye to the enshitified Web!
Open source RSS readers I highly recommend are 'NetNewsWire' on iOS and MacOS (my favourite so far) and 'Capy Reader' or 'Read You' on Android.
I have one on Mint, but can't remember its name. I'm away for the weekend and cannot check right now, but I will update here tomorrow evening or Monday morning once I'm back home.
Having said that, while it gets the job done, it's my least favourite.
A Linux fork of NetNewsWire would be ideal.

@MichaelOpal @pluralistic I would not even know how to start using RSS.
Are there any clients that don't make it feel like email, like another digital chore?
Maybe a little bit 'advanced' usage: I follow some projects or more concrete their releases via rss to get a notification everytime a new version is released. Works on github not sure about codeberg.
@pluralistic
You can roll your own reader!
This weekend I built my own locally hosted rss+ reader. Yes, used Claude.
Why? I want features, my features & cuz I can now, thx Claude. No worries about sunset, lives on NAS.
My Features? Crawler enhanced, Jina API allows me to scrape pages without rss or decent html feeds. Jina also does tagging and categorization, creates summary cards for every story. The next layer creates briefs of any feed with LLM. Great read aloud too.
@pluralistic 'Of course, tying individual executives' bonuses to making a number go up has a predictably perverse outcome. As Goodhart's law has it, "Any metric becomes a target, and then ceases to be a useful metric.'
We're living this in the Salesforce ecosystem right now. They recently replaced all their well-functioning support forms with agents powered by their bet-the-company AI bots. And the outcome is predictable: it's twice as hard for partners and customers to get the specific help they need, and which they knew how to easily get from the support forms. Many of these forms kicked off automated processes that are essential to partner business. Now you have to argue with a bot that gets things wrong, requires more effort to interact with, and acts as a case deflection tool. All because someone had a number-go-up metric to meet.
@pluralistic I wrote and have been been using my own feed reader, Temboz, for over 24 years now. The two essential features of any good reader in my book are:
1) filtering. Don't want to hear about the inane Kardashians or the insane Trump any more? Double-click on their occurrence, click "thumbs-down", adjust the filtering setting and boom, mental health restored.
2) giving you control over the order articles are shown, as opposed to the Meta or Google algorithm that does not have your best interests at heart.
@viq I am actually in the middle of rewriting it in Rust, and switched my own usage yesterday, so if I were you I'd hold off for a couple of weeks until it stabilizes:
@viq OK, use rTemboz, follow the Docker instructions at https://github.com/fazalmajid/rTemboz?tab=readme-ov-file#running
(you don't need to build from source if you are OK using my docker images on Docker Hub).
I am dogfooding rTemboz at the moment, I am intensely aware of the regressions and highly motivated to fix them as this is the single app I spend the most time in...
@viq Either you build your tag hierarchies, which is a drag, , or you have a LLM classifier do this according to a taxonomy you choose, or you implement some form of vector search with embeddings. I don't want rTemboz to require a GPU to run. The data model already supports human entered tags vs AI, but the infrastructure to actually do it isn't in place yet. And some people have deep objections to LLMs.
Assuming you don't, what would be your preference for integrating AI assistance: self-hosted, API, CPU only, etc?
@fazalmajid
Personally I'd rather not get LLMs involved in this. Thus my idea of "saved search" (if searching for articles is possible), and/or rules for applying tags to articles or otherwise support for "virtual folders" with "some" mechanism for making articles appear in them.
I wonder how well Bayesian analysis would work for such?
Oh, also, does (r)Temboz support fetching full articles if feed has only snippets?
@viq yes, it has full-text search using SQLite's fts5, but not semantic search. It does not fetch full feeds, I've been on the receiving end of a DMCA take-down for just publishing a feed of the articles I personally find interesting.
You don't need a LLM to classify, an embedding like SBERT, GTE or Microsoft E5 combined with vector search would suffice, unless you are philosophically opposed to any kind of neural net tech.
Have you tried it yet? Any first impressions you'd like to share?
@fazalmajid
Huh. Damn, that's trigger-happy :(
LLMs to my knowledge require models to be of any use, and currently AFAIK all of those are of dubious origin. The current situation and how LLMs under a marketing term are shoved into everything, and the wide lens view of "why" is what soured that particular technology for me. AFAIK neural nets are just underlying tech, shared with other uses, and do not require ingesting all of everything without compensation to do useful things.