Giant Corporations™ are scraping my little git server to feed their ever-hungry, planet-destroying plagiarism machines.
So now, instead of getting my code, they get a 10GB treat.
Fucking THIEVES.
edit: This was inspired-by-and-based-on this post https://rknight.me/blog/blocking-bots-with-nginx/

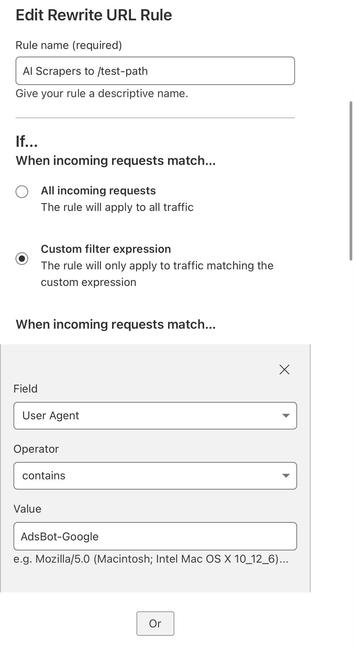
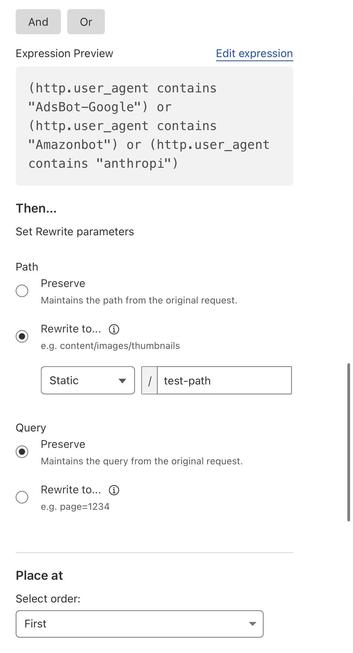
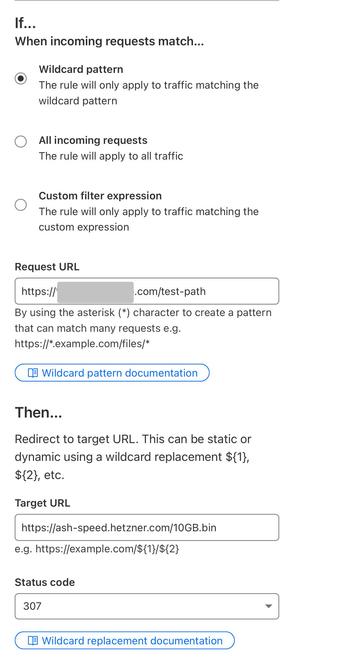





 minor!
minor!




 @Revision
@Revision