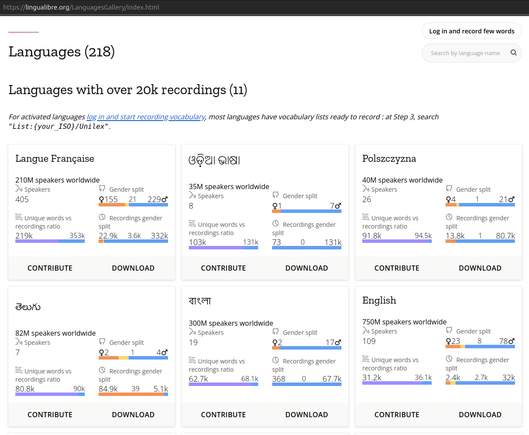
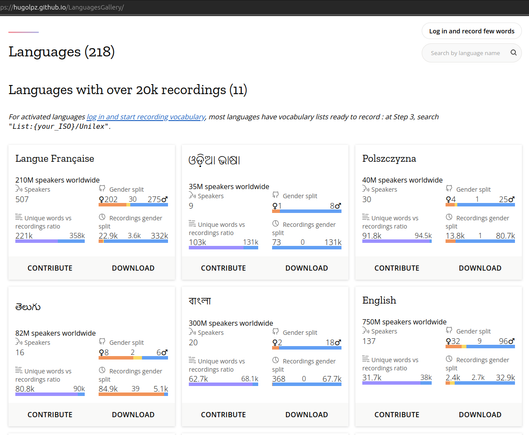
Long and fiery winter night it is ! User:Dragons_Bot is importing frequency lists in 500 more #languages from Unilex into #Lingualibre. Dragons Bot script is running tonight, editing Lili persistently. We then will have common words list for 1001 languages, ready for you to record. At step 3 of the Recording Studio, click "local list", then search List:{your_iso}/Unilex and you are good to go ! If your community's languages aren't there you can let me know below. 🎉
https://lingualibre.org/wiki/Special:RecordWizard
https://lingualibre.org/wiki/Special:RecordWizard