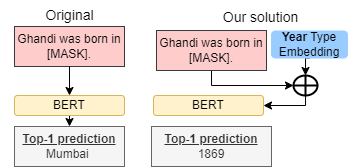
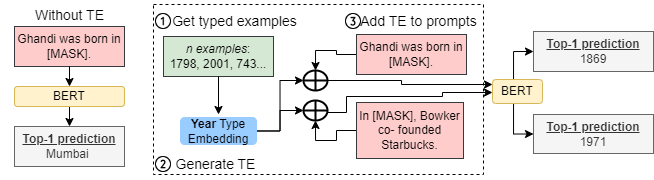
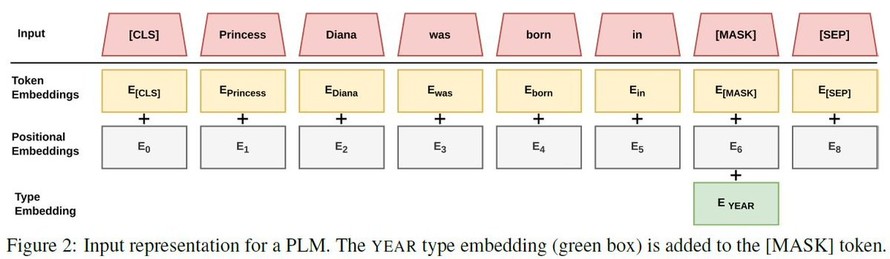
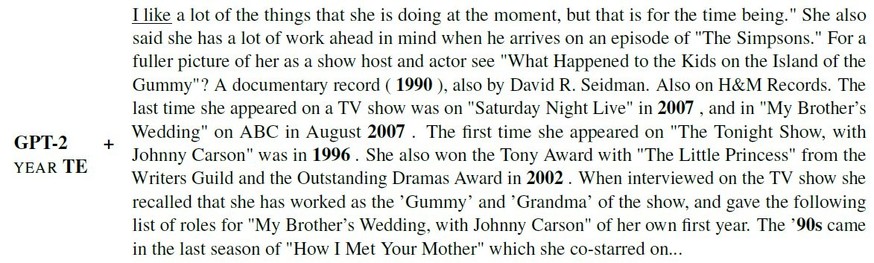
“Gandhi was born in __.” Should this #prompt return 'India' or '1869'?
Our #EMNLP2022 #paper (w. M. Saeed) shows how #embeddings can enforce the desired typed output, such as Country or Year, in factual #probing.
https://www.eurecom.fr/publication/7095/download/data-publi-7095.pdf
🧵👇[1/6]
Our #EMNLP2022 #paper (w. M. Saeed) shows how #embeddings can enforce the desired typed output, such as Country or Year, in factual #probing.
https://www.eurecom.fr/publication/7095/download/data-publi-7095.pdf
🧵👇[1/6]