Home
Explore
mastodon.social
mstdn.social
infosec.exchange
mstdn.jp
social.vivaldi.net
piaille.fr
hachyderm.io
mastodon.world
troet.cafe
m.cmx.im
mastodon.uno
mastodon.gamedev.place
techhub.social
social.tchncs.de
mastodon.nl
norden.social
kolektiva.social
flipboard.social
mathstodon.xyz
mastoturk.org
nrw.social
occm.cc
tech.lgbt
mastodonapp.uk
universeodon.com
mstdn.ca
defcon.social
c.im
masto.es
toot.community
sueden.social
mstdn.party
det.social
sfba.social
mastodon.scot
ohai.social
ruhr.social
mastodon.ie
tkz.one
hessen.social
mastodontech.de
mastodon.nu
livellosegreto.it
pouet.chapril.org
mastodon.au
social.linux.pizza
ioc.exchange
mastodont.cat
social.cologne
indieweb.social
ieji.de
mastodon.eus
mastodon.sdf.org
mastodon.bida.im
feuerwehr.social
social.anoxinon.de
mastodon.green
muenchen.social
wehavecookies.social
masto.nu
cyberplace.social
nerdculture.de
mindly.social
ruby.social
mastodon.ml
metalhead.club
phpc.social
uri.life
m.otter.homes
mastodontti.fi
dresden.network
toot.wales
sunny.garden
climatejustice.social
noc.social
sciences.social
bark.lgbt
mstdn.plus
woof.tech
privacysafe.social
furry.engineer
freiburg.social
tooting.ch
mastouille.fr
rollenspiel.social
hostux.social
mastodon.me.uk
rivals.space
blorbo.social
mastodon.com.pl
bonn.social
mast.lat
mastorol.es
rheinneckar.social
urbanists.social
mastoart.social
wien.rocks
mastodon-belgium.be
discuss.systems
gaygeek.social
ursal.zone
expressional.social
todon.nl
h4.io
masto.pt
mapstodon.space
mstdn.games
glasgow.social
hcommons.social
snabelen.no
sakurajima.moe
cupoftea.social
lgbtqia.space
shelter.moe
darmstadt.social
tilde.zone
mastodon.gal
fairy.id
retro.pizza
urusai.social
ludosphere.fr
qdon.space
muenster.im
bookstodon.com
peoplemaking.games
pawb.fun
toot.aquilenet.fr
mastodon.berlin
mast.dragon-fly.club
veganism.social
socel.net
famichiki.jp
freeradical.zone
kanoa.de
vmst.io
mstdn.dk
union.place
theblower.au
toad.social
machteburch.social
witter.cz
mastodon.uy
xarxa.cloud
oslo.town
eupolicy.social
qaf.men
burningboard.net
tooot.im
fandom.ink
musicworld.social
mstdn.business
stranger.social
tea.codes
disabled.social
mountains.social
masto.nyc
4bear.com
graphics.social
cultur.social
pnw.zone
gardenstate.social
fedi.at
hear-me.social
furries.club
mustard.blog
mastodon.pnpde.social
thecanadian.social
musician.social
bahn.social
toot.re
toot.kif.rocks
musicians.today
dizl.de
libretooth.gr
ciberlandia.pt
babka.social
archaeo.social
tyrol.social
dmv.community
tuiter.rocks
ani.work
vkl.world
frikiverse.zone
mastodon.energy
masto.nobigtech.es
lou.lt
gamepad.club
social.seattle.wa.us
drupal.community
donphan.social
tchafia.be
social.silicon.moe
mast.hpc.social
is.nota.live
bzh.social
mastodon.vlaanderen
fulda.social
toot.si
puntarella.party
muri.network
hometech.social
social.politicaconciencia.org
lsbt.me
wargamers.social
mograph.social
norcal.social
datasci.social
devianze.city
toot.funami.tech
theatl.social
opencoaster.net
mastodon.africa
genealysis.social
hispagatos.space
drumstodon.net
est.social
epicure.social
toot.garden
elekk.xyz
colorid.es
mastodon.pirateparty.be
indieauthors.social
mastodon.london
friendsofdesoto.social
apobangpo.space
mastodon.cr
hoosier.social
mstdn.animexx.de
mastodon.education
lewacki.space
kurry.social
burma.social
leipzig.town
planetearth.social
ruhrpott.social
esq.social
frontrange.co
fikaverse.club
mastodon.bot
techtoots.com
raphus.social
library.love
fairmove.net
khiar.net
toots.nu
rail.chat
mastodon-swiss.org
fribygda.no
rheinhessen.social
h-net.social
arvr.social
opalstack.social
mastodon.wien
seocommunity.social
poweredbygay.social
mastodon.free-solutions.org
mastodon.sg
bologna.one
epsilon.social
k8s.social
stereodon.social
growers.social
camp.smolnet.org
okla.social
mastodon.cipherbliss.com
mastodon.hosnet.fr
elizur.me
birdon.social
paktodon.asia
masto.yttrx.com
skastodon.com
episcodon.net
squawk.mytransponder.com
biplus.social
mastodon.babb.no
mastodon.frl
lounge.town
cville.online
balkan.fedive.rs
mastodon.iow.social
23.illuminati.org
silversword.online
mastodon.ph
kzoo.to
mastodon.bachgau.social
mastodon.ee
mcr.wtf
social.diva.exchange
synapse.cafe
social.ferrocarril.net
kcmo.social
troet.fediverse.at
nfld.me
voi.social
nautical.social
mastodon.mg
mikumikudance.cloud
mastodon.bahia.no
polsci.social
darticulate.com
dariox.club
ms.maritime.social
fpl.social
nomanssky.social
kjas.no
bvb.social
nwb.social
social.sndevs.com
netsphere.one
ceilidh.online
nutmeg.social
learningdisability.social
wxw.moe
computerfairi.es
Log In
Show thread
Paolo Papotti
Nov 7, 2022
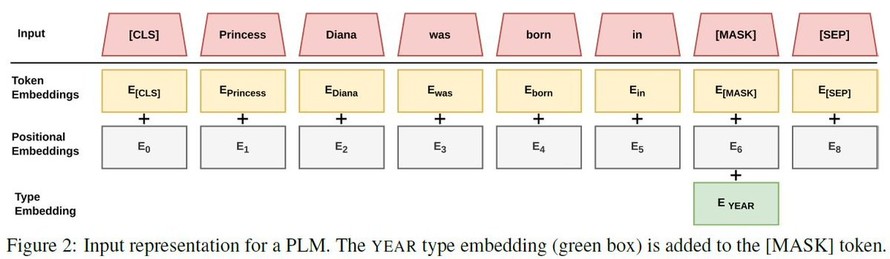
Given the type embedding (TE), we simply add it to the mask token in the prompt for
#factretrieval
. The TE steers the inference of the target
#token
towards the desired type. No training, no
#finetuning
, just add the new embedding to the input. 3/6
1
0
0