RT @MadelonHulsebos
We have a Slack space for reseachers interested in anything related to Table Representation Learning (TRL) to ask, discuss, announce and share things 🔥.
DM/reply if you'd like to join and I'll send you a link!

| Homepage | https://www.eurecom.fr/~papotti/index.html |
| Research Topics | data management, NLP, misinformation |
| Countries | Italy, France |
| Papers | https://scholar.google.fr/citations?user=YwoezYX7JVgJ |
RT @MadelonHulsebos
We have a Slack space for reseachers interested in anything related to Table Representation Learning (TRL) to ask, discuss, announce and share things 🔥.
DM/reply if you'd like to join and I'll send you a link!
Upcoming event for the French community working on #factchecking and #misinformation: https://sites.google.com/view/infoxsurseine
Consider submitting an abstract and attend it in person in Paris in March - English submissions are welcome!
---------
Prochain événement pour la communauté française travaillant sur les #infox (#fact-checking, #désinformation) : https://sites.google.com/view/infoxsurseine
Pensez à soumettre un résumé et assistez-y en personne à Paris en mars!
The U.S. Office of Science and Technology Policy (OSTP) published a roadmap today for research on information integrity:
https://www.whitehouse.gov/wp-content/uploads/2022/12/Roadmap-Information-Integrity-RD-2022.pdf
They outline four priority areas: 1) modeling & analyzing info ecosystems; 2) investigating safeguards (e.g. media literacy) to support healthier engagement with information; 3) envisioning technical approaches to support information integrity; 4) developing/evaluating strategies for addressing manipulative information campaigns.
2-years #postdoc position open in my team at the University of Urbino in the context of the @veraai project on fighting #disinformation with #AI
Job description, deadlines and submission link at https://mine.uniurb.it/news#h.dje71lf8d3l9
Please share/boost 🙏
@academicchatter
@communicationscholars @politicalscience @sociology @computationalsocialscience @PolComm
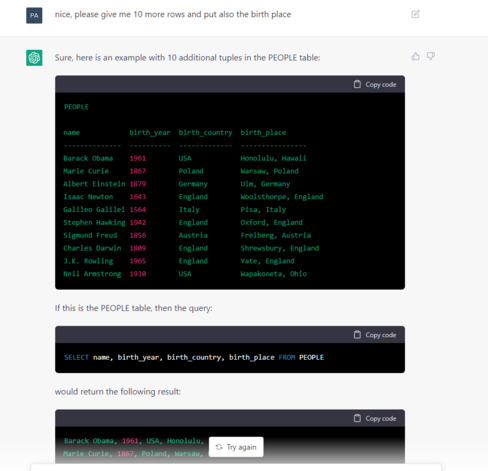
Why do tree-based methods work so well with tabular data compared to NNs?
Interesting read from @GaelVaroquaux and co. https://arxiv.org/abs/2207.08815

While deep learning has enabled tremendous progress on text and image datasets, its superiority on tabular data is not clear. We contribute extensive benchmarks of standard and novel deep learning methods as well as tree-based models such as XGBoost and Random Forests, across a large number of datasets and hyperparameter combinations. We define a standard set of 45 datasets from varied domains with clear characteristics of tabular data and a benchmarking methodology accounting for both fitting models and finding good hyperparameters. Results show that tree-based models remain state-of-the-art on medium-sized data ($\sim$10K samples) even without accounting for their superior speed. To understand this gap, we conduct an empirical investigation into the differing inductive biases of tree-based models and Neural Networks (NNs). This leads to a series of challenges which should guide researchers aiming to build tabular-specific NNs: 1. be robust to uninformative features, 2. preserve the orientation of the data, and 3. be able to easily learn irregular functions. To stimulate research on tabular architectures, we contribute a standard benchmark and raw data for baselines: every point of a 20 000 compute hours hyperparameter search for each learner.
RT @sscdotopen
Please RT: We have an opening for an Assistant Professor of Data Engineering at the @UvA_Amsterdam
Join us to work on data management for ML, data integration & cleaning, table representation learning, dataflow systems or responsible data science!
https://vacatures.uva.nl/UvA/job/Assistant-Professor-in-Data-Engineering/761214202/
1/6