Three new Kitten TTS models – smallest less than 25MB
https://github.com/KittenML/KittenTTS
#HackerNews #KittenTTS #KITTENML #TextToSpeech #AIModels #SmallModels
Three new Kitten TTS models – smallest less than 25MB
https://github.com/KittenML/KittenTTS
#HackerNews #KittenTTS #KITTENML #TextToSpeech #AIModels #SmallModels
Remember when computer-generated voices and virtual pop idols were cool and cute and a completely new and exciting music genre and not the constant background noise of our horrifying computerized dystopia? Pepperidge Farm remembers. Man this is a bop, even a decade and a half later.
https://www.youtube.com/watch?v=duPJqfKiA78
#hatsunemiku #vocaloid #texttospeech #baka #triplebaka #music #synthesizer #electro #jpop

Fish Audio has open-sourced S2, a #texttospeech model that supports fine-grained inline control of prosody and emotion using natural-language tags like [laugh], [whispers], and [super happy]
#Business #Guides
Your browser can already speak a page · How to activate read-aloud features on web pages https://ilo.im/16b5hy
_____
#Reading #Audio #Accessibility #TextToSpeech #Text #Content #Webpages #Browsers
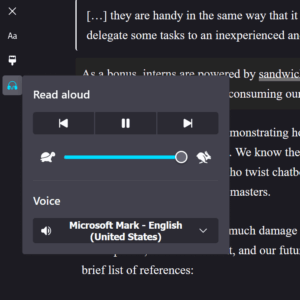
Users can customize the features built into the browser, something not often available from third-party approaches. Is an “AI” company offering to provide spoken versions of your pages for users? Is an overlay company promising to make your content more accessible by its overlay speaking it? Is some other vendor…
Google AI Studio — The Only App Builder You’ll Ever Need
We should do a crowdfunding campaign for a "Starcraft Terran siege tank driver" text-to-speech voice for Piper, so that Orca can angrily read GTK widgets at you with this kind of confident and upbeat intonation: https://youtu.be/dtoIv9BzPHk?t=16

#6. СКЛЕЙКА (БЕЗ ПОТЕРИ КАЧЕСТВА)
ls "WORKDIR"/part_*.mp3 | sort | xargs -I {} echo "file '{}'" > "WORKDIR/list.txt"
ffmpeg -f concat -safe 0 -i "WORKDIR/list.txt" -c copy -y "FINAL_FILE" > /dev/null 2>&1
rm -rf "WORKDIR"
echo "ГОТОВО! Файл: FINAL_FILE"
#4. ОБРАБОТКА ТЕКСТА И НАРЕЗКА
sed '/^/d' "WORKDIR/raw.txt" > "WORKDIR/source.txt"
fold -s -w 2000 "WORKDIR/source.txt" | tr -d '\r' > "WORKDIR/formatted.txt"
split -l 100 -d -a 4 "WORKDIR/formatted.txt" "WORKDIR/part_"
TOTAL_PARTS=(ls "$WORKDIR"/part_[0-9]* | wc -l)
#5. КОНВЕЙЕРНАЯ ОЗВУЧКА
export VOICE WORKDIR RATE
do_tts() {
local file=1
edge-tts --rate="RATE" --voice "VOICE" --file "file" --write-media "$file.mp3" > /dev/null 2>&1
}
export -f do_tts
#Очередь через xargs (вот здесь живет скорость)
ls "WORKDIR"/part_[0-9]* | xargs -P THREADS -I {} bash -c 'do_tts "{}"'