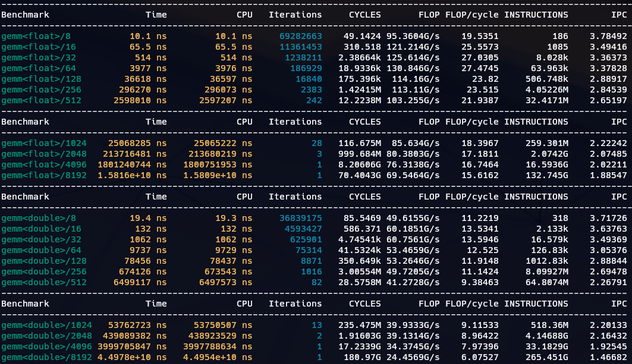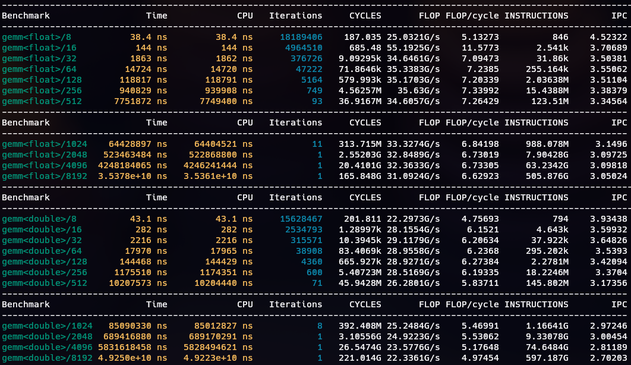
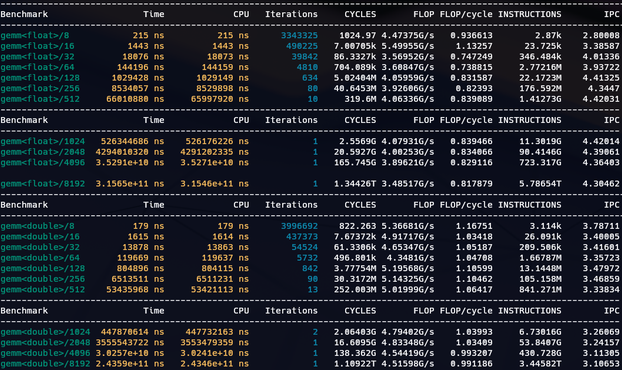
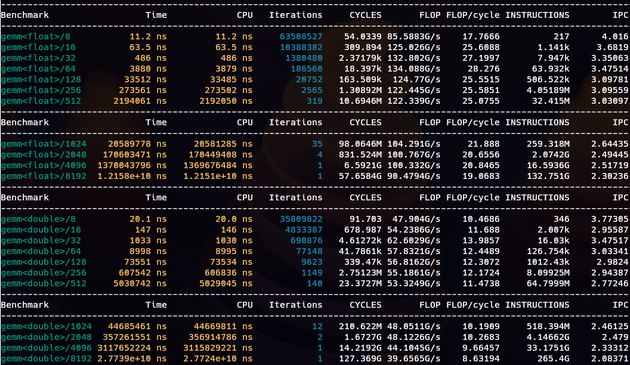
I've been looking into matrix multiplication using std::simd and std::mdspan/submdspan (all single-threaded).
I got to 86% of peak FLOP. x86_64 AVX2 has 32/16 FLOP/cycle peak (2 FMAs per cycle).
I suspect better performance needs a more cache-friendly layout mapping. This is using layout_right.