 Qiita - 人気の記事
Qiita - 人気の記事This MicroAdam paper from #NeurIPS2024 is nicely written! The algorithm is walked through in plain language first, and all the equations and proofs placed in the appendix. Super understandable, kudos to the authors.
https://arxiv.org/abs/2405.15593
#AI #MachineLearning #LLMs #optimizers

MicroAdam: Accurate Adaptive Optimization with Low Space Overhead and Provable Convergence
We propose a new variant of the Adam optimizer called MicroAdam that specifically minimizes memory overheads, while maintaining theoretical convergence guarantees. We achieve this by compressing the gradient information before it is fed into the optimizer state, thereby reducing its memory footprint significantly. We control the resulting compression error via a novel instance of the classical \emph{error feedback} mechanism from distributed optimization in which *the error correction information is itself compressed* to allow for practical memory gains. We prove that the resulting approach maintains theoretical convergence guarantees competitive to those of AMSGrad, while providing good practical performance. Specifically, we show that MicroAdam can be implemented efficiently on GPUs: on both million-scale (BERT) and billion-scale (LLaMA) models, MicroAdam provides practical convergence competitive to that of the uncompressed Adam baseline, with lower memory usage and similar running time. Our code is available at https://github.com/IST-DASLab/MicroAdam.
In the latest FCAI #Newsletter:
- 2024 Year in Review
- #NeurIPS2024 papers from 🇫🇮
- This year's #machinelearning Nobel Prizes
- Plus, we are #hiring postdocs, PhD students and research fellows!
Read more here: https://mailchi.mp/a1bf1808b285/fcai-newsletter-17450216

Julen Etxaniz, Imanol Miranda eta Gorka Azkune Vancouverren egon dira #NeurIPS2024 konferentzian beren lana aurkezten.




My #NeurIPS2024 summary:
- Keynote racism 😱☠️https://x.com/xwang_lk/status/1867819741722948005
- Best Paper ethical dumpster fire 🔥 https://var-integrity-report.github.io/
- tiny but non-zero roundtable on 'harms of AI' (facilitated by yrs truly) https://creativity-ai.github.io/ 😁✊
- Keynote racism 😱☠️https://x.com/xwang_lk/status/1867819741722948005
- Best Paper ethical dumpster fire 🔥 https://var-integrity-report.github.io/
- tiny but non-zero roundtable on 'harms of AI' (facilitated by yrs truly) https://creativity-ai.github.io/ 😁✊

Xin Eric Wang @ NeurIPS 2024 (@xwang_lk) on X
It is just so sad that the #NeurIPS2024 main conference ended with such a racist remark by a faculty when talking about ethics. How ironic! I also want to commend the Chinese student who spoke up right on spot. She was respectful, decent, and courageous. Her response was
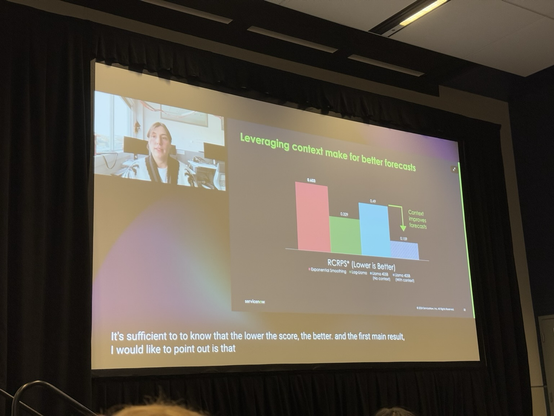
Incorporating context into forecasting improves performance on average. Llama 3.1 405b seems to work best. Great talk by Valentina Zantedeschi (ServiceNow) at the time-series workshop at #neurips24 #NeurIPS #NeurIPS2024 #AI #LLM



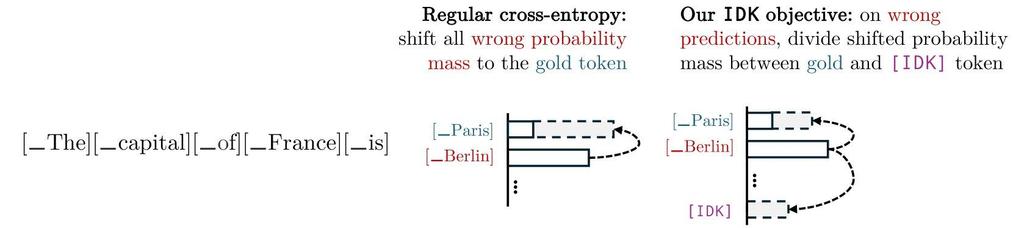
LLMs "hallucinate" by making up information instead of revealing their lack of knowledge 🤔
Our #NeurIPS2024 paper adds an [I-Don't-Know] 🤷🏾♂️ token to the LLM and fine-tunes it to predict this instead of hallucinating.
1/2

LLMs "hallucinate" by making up information instead of revealing their lack of knowledge 🤔
Our #NeurIPS2024 paper adds an [I-Don't-Know] 🤷🏾♂️ token to the LLM and fine-tunes it to predict this instead of hallucinating.
No extra annotation is needed for training! Our IDK objective divides the shifted probability mass between the gold token and I-Don't-Know token for wrong predictions.
Details in the paper👉🏾 https://arxiv.org/abs/2412.06676v1
w/ Roi Cohen, Konstantin Dobler, Eden Biran
I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token
Large Language Models are known to capture real-world knowledge, allowing them to excel in many downstream tasks. Despite recent advances, these models are still prone to what are commonly known as hallucinations, causing them to emit unwanted and factually incorrect text. In this work, we propose a novel calibration method that can be used to combat hallucinations. We add a special [IDK] ("I don't know") token to the model's vocabulary and introduce an objective function that shifts probability mass to the [IDK] token for incorrect predictions. This approach allows the model to express uncertainty in its output explicitly. We evaluate our proposed method across multiple model architectures and factual downstream tasks. We find that models trained with our method are able to express uncertainty in places where they would previously make mistakes while suffering only a small loss of encoded knowledge. We further perform extensive ablation studies of multiple variations of our approach and provide a detailed analysis of the precision-recall tradeoff of our method.
Great talk by Sander Dieleman (@sedielem, Google Deepmind and @UGent alumnus) at #NeurIPS2024 Workshops in Vancouver, BC (Canada) on autoregression vs diffusion for iterative refinement. Visit his great blog: https://sander.ai #NeurIPS #AI
We have lift off at the #NeurIPS2024 Workshops in Vancouver, BC (Canada). I decided to focus on Adaptive Foundation Models. #LLM #largelanguagemodels #finetuning #RAG #RatrievalAugmentedGeneration #NeurIPS
