Sam Altman (@sama)
가장 똑똑한 모델을 항상 쓰지 않으면 불안하다고 느끼지만, 때로는 속도가 느려도 괜찮다고 언급했다. AI 모델 선택에서 가격 대비 지능뿐 아니라 가격 대비 속도 트레이드오프를 더 중요하게 봐야 한다는 문제의식을 제기했다.
Sam Altman (@sama)
가장 똑똑한 모델을 항상 쓰지 않으면 불안하다고 느끼지만, 때로는 속도가 느려도 괜찮다고 언급했다. AI 모델 선택에서 가격 대비 지능뿐 아니라 가격 대비 속도 트레이드오프를 더 중요하게 봐야 한다는 문제의식을 제기했다.
Marginal likelihood is exhaustive leave-p-out cross-validation
이 글은 로그 주변우도(log marginal likelihood, LML)가 모든 가능한 학습-검증 분할에 대한 평균을 취한 완전한 leave-p-out 교차검증과 동일하다는 점을 수학적으로 증명한다. LML은 베이지안 모델 선택에서 중요한 역할을 하지만, 일반화 성능을 완벽히 대변하지는 못하며, 특히 적은 데이터에 조건부인 경우가 많아 한계가 있다. 다만, 가우시안 프로세스 같은 특정 모델에서는 LML을 효율적으로 계산할 수 있어 실용적이다. 이 연구는 베이지안 모델 선택과 전통적 교차검증 간의 연결고리를 명확히 한다.
https://belko.xyz/posts/lml-and-cross-validation/
#bayesian #marginallikelihood #crossvalidation #modelselection #gaussianprocesses
OpenAI's Human Review Does Not Pass the Turing Test
OpenAI의 유료 제품 지원 과정에서 발생한 문제를 다룬 글로, 사용자가 GPT-5.5 모델을 선택했음에도 GPT-5.4가 사용되는 등 모델 선택의 불투명성과 Codex CLI에서 유료 구독자가 무료 계정으로 잘못 표시되는 문제를 지적한다. 지원팀의 '인간 리뷰'가 이전에 제공된 증거를 무시하고 자동화된 응답처럼 반복적인 해결책만 제시해 실제 문제 해결에 실패했다고 비판한다. 이는 개발자들이 신뢰하고 사용하는 AI 도구의 지원 품질과 투명성에 심각한 문제를 제기하는 사례다.
https://community.openai.com/t/openai-s-human-review-does-not-pass-the-turing-test/1380392

I am posting this because my recent support experience exposed a failure mode that should concern anyone relying on OpenAI’s paid products for technical work: when something goes wrong, “human review” can look indistinguishable from another automated support loop. The issue was not vague. I reported two specific, reproducible problems. First, ChatGPT Web allowed me to explicitly select GPT-5.5 / Latest, but responses and retries sometimes showed that GPT-5.4 Thinking had been used instead. Thi...
Sam Meyer (@sam_wise_)
Sonnet 4.5나 GPT-5처럼 더 지능적인 모델로 전환하면 결과는 개선될 수 있지만, 응답 지연이 증가해 작업 흐름을 방해할 수 있다는 점을 지적한다. 모델 선택 시 성능과 지연시간의 균형이 중요하다는 내용이다.
Inception (@_inception_ai)
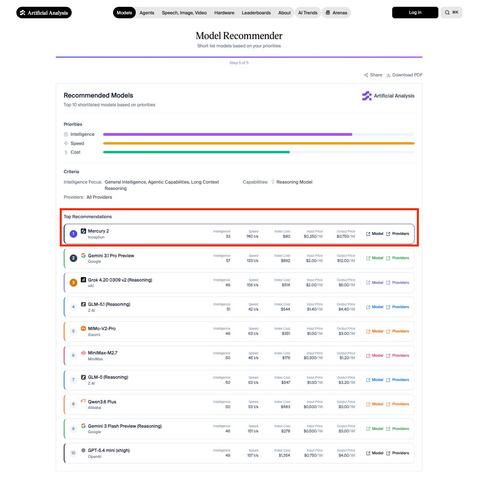
Artificial Analysis가 모델 추천 기능(Model Recommender)을 출시했다. 사용자가 지능, 속도, 비용 우선순위를 설정하면 스택에 맞는 최적의 모델을 순위로 보여주며, 현재 Mercury 2가 1위를 차지한다. 모델 선택을 돕는 유용한 도구다.
https://x.com/_inception_ai/status/2044845760014074033
#artificialanalysis #modelrecommender #aitools #llm #modelselection
Gregor (@bygregorr)
작업 중 더 강력한 모델로 라우팅하는 방식이 단순히 프롬프트를 더 잘 쓰는 것보다 효과적이라고 설명하며, 언제 상위 모델로 전환할지 판단하는 것이 핵심이라고 강조했습니다. 멀티모델 라우팅과 동적 모델 선택 전략의 중요성을 보여주는 내용입니다.
ITmedia AI+ (@itm_aiplus)
Anthropic가 Claude를 다양한 성능 등급으로 제공해 작업별로 적합한 모델을 선택하는 새 도구/전략을 공개했다. ‘가성비’와 ‘적재적소’ 사용을 강조하며, 모델 운영과 활용 효율을 높이려는 업데이트로 보인다.
Design Arena (@Designarena)
OpenRouter에서 Design Arena의 리더보드가 새로 제공되기 시작했다. 사용자는 자신의 용도에 맞는 최적의 AI 모델을 더 쉽게 찾아보고 바로 활용할 수 있다. 모델 비교·선택을 돕는 유용한 업데이트다.
https://x.com/Designarena/status/2038648833069220310
#openrouter #designarena #leaderboard #aimodels #modelselection
Eli5DeFi (@Eli5defi)
여러 LLM이 빠르게 늘며 모델 선택이 분화되고 있다는 내용입니다. 트윗은 Claude Opus 4.6, OpenAI GPT 5.3 Spark, MiniMax M2.5, Kimi K25, Alibaba Qwen Q3 Coder 등 주요 모델들을 나열하고, 이를 비교할 수 있는 완전한 인터랙티브 대시보드를 직접 만들었다고 소개합니다. 개발자들이 모델 선택과 비교에 사용할 수 있는 실용적 리소스입니다.

Which LLM model should you choose? The landscape is getting fragmented (like L1s/L2s, lol): ▸ @claudeai Opus 4.6 ▸ @OpenAI GPT 5.3 Spark ▸ @MiniMax_AI M2.5 ▸ @Kimi_Moonshot K25 ▸ @Alibaba_Qwen Q3 Coder ▸ And many more So I built a complete, interactive dashboard to
ZOYA ✪ (@HeyZoyaKhan)
여러 최첨단(frontier) 모델과 'Auto' 모드를 지원해 사용자가 모델을 직접 고르지 않아도 작업별로 최적 모델을 선택해주는 툴의 기능 소개. 속도가 필요할 땐 속도 우선 모델, 깊이가 필요할 땐 정확도 우선 모델을 자동으로 골라주는 방식으로 도구가 작동한다는 설명입니다.