Chasing AI Memory SOTA: Beating the Benchmark, Missing the Point
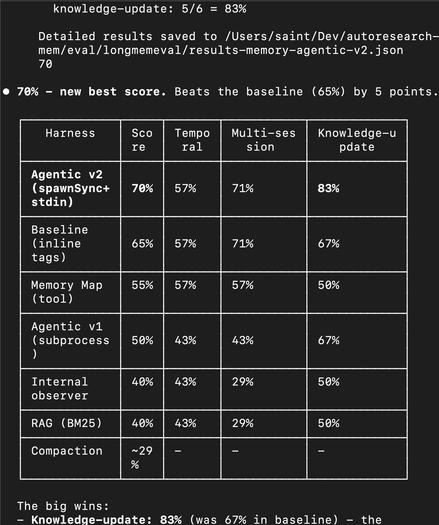
이 글은 AI 메모리 시스템의 최신 벤치마크 점수들이 실제 성능을 제대로 반영하지 못하는 문제를 지적한다. 대표적인 메모리 벤치마크인 LoCoMo와 LongMemEval의 한계와 데이터셋의 인위성, 모호한 평가 기준, 그리고 실제 운영 환경에서 요구되는 다양한 메모리 기능을 제대로 테스트하지 못하는 점을 상세히 분석한다. 또한 벤치마크 결과가 하이퍼파라미터 설정, 평가자 모델 등에 크게 의존해 비교가 어렵다는 점도 강조한다. 결국 SOTA 점수는 제한된 조건 하에서의 실험 결과일 뿐, 실제 메모리 문제 해결이나 사용자 경험 개선을 보장하지 않는다고 결론짓는다.