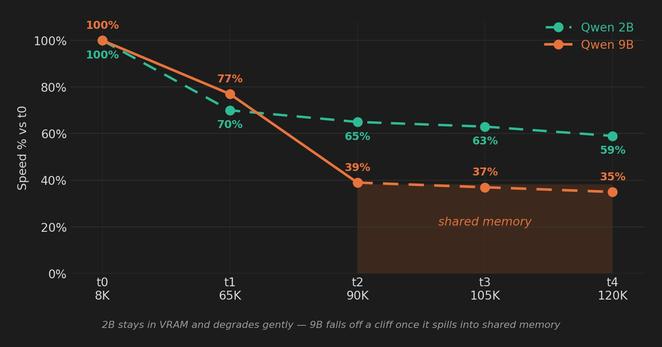
Your local LLM runs fine until it doesn't. A look at KV cache spilling from VRAM into shared memory, and why it happens silently on Windows. https://hackernoon.com/why-local-llms-suddenly-slow-down-at-long-context #localllms
cleaning out my computer to make space for #localLLMs. the biggest file on here is a 40GB Twitch VOD of me streaming my first time playing Overwatch 2 for my friends in chat. 4K & 60FPS but 1) i was so bad at the game 2) the OBS sound mixing was horrendous -- you can hardly hear how sad i was about Blizzard killing OW1. there is no way i am deleting this lol. the memories! #rip #overwatch #activision_blizzard
J'ai pris un moment pour jouer avec les données de #LLM de @betagouv
👉 https://comparia.beta.gouv.fr/ranking
Un modèle local capable consomme 40 à 120x moins d'énergie par token qu'un frontier!!!
Pour mon cas, utiliser les modèles locaux pour le "quotidien" (rédaction, brainsto, recherches) et garder les API frontier seulement pour le dev, c'est ❗une emprunte carbone divisée par 80❗
+ la confidentialité des données :))
Note : la conso comparIA est un ordre de grandeur
Classement - compar:IA, le comparateur d'IA conversationnelles
compar:IA est un outil permettant de comparer à l’aveugle différents modèles d'IA conversationnelle pour sensibiliser aux enjeux de l'IA générative (biais, impact environmental) et constituer des jeux de données de préférence en français.
NVIDIA's RTX Spark brings CUDA and 128GB unified memory to mainstream Windows PCs this fall. The move reshapes local-AI hardware decisions: the question shifts from 'buy the biggest card you can afford' to 'which constraint fails first—memory, bandwidth, or model quality.' https://www.implicator.ai/nvidias-rtx-spark-splits-the-local-ai-hardware-decision-in-two/ #AI #Hardware #LocalLLMs

NVIDIA's RTX Spark Splits the Local AI GPU Decision
NVIDIA's RTX Spark drops CUDA and 128GB of unified memory into mainstream Windows PCs, sharpening a local-AI buying decision that now turns on what fails first: memory capacity, bandwidth, or model quality. What an individual and a startup should actually buy in 2026, and where to stop spending.
Mein #arbeitgeber labert grade in so nem #MicrosoftTeams Call für alle Mitarbeiter was von #digitalesouveranitat und dann soll ich MEHR mit #microsoft #github #copilot machen. Und selbstverständlich wird ALLES #ai. Sogar unsere TLD wechselt von .net auf .ai.
Wir sollen ganz explizit doch bitte #ki in die tägliche #Arbeit einbinden, der Vertrieb von KI schwärmen. Aber bloß "unsere" nutzen, wegen den Daten. Muss mich gleich mal informieren, ob #localLLMs erlaubt sind.
https://hessen.social/@Moonstone2487/116082676681677166
Wir sollen ganz explizit doch bitte #ki in die tägliche #Arbeit einbinden, der Vertrieb von KI schwärmen. Aber bloß "unsere" nutzen, wegen den Daten. Muss mich gleich mal informieren, ob #localLLMs erlaubt sind.
https://hessen.social/@Moonstone2487/116082676681677166
Mini PC for local LLMs in 2026

Switched qwen3.5:4b from cloud to the Mac Mini and cut Spellcast API calls by ninety percent. Tinyvision tasks that once bled credits now run locally in seconds.
Running Local LLMs Offline on a Ten-Hour Flight
https://deploy.live/blog/running-local-llms-offline-on-a-ten-hour-flight/
#HackerNews #LocalLLMs #Offline #Flight #Technology #AIApplications #TravelTech
Running Local LLMs Offline on a Ten-Hour Flight
Update, 29 April 2026 This post was picked up on Hacker News and crossed 100 comments. I love that this sparks emotions. As always, there is a fair mix of reactions, which is exactly what you would expect from HN. Scroll to the bottom for extra responses to some of the comments. … Cloud Next was intense. I wrote the first version of this post at 9am my time while dozing off, and I did not expect much interest in it. Given the attention it is now getting, I gave the post the attention it deserved: corrected the model details, added more context about the setup, and responded to the most common points.
How to Run #LocalLLMs with #ClaudeCode
