金のニワトリ (@gosrum)
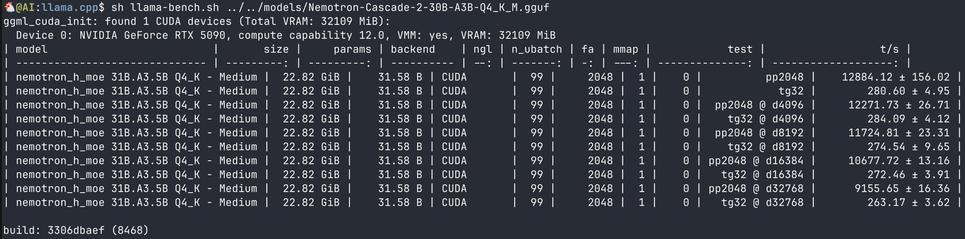
RTX 5090 환경에서 Nemotron-Cascade-2-30B-A3B(Q4_K_M)의 llama-bench 결과를 공유했다. prefill은 약 13000 tps, decord는 약 285 tps로, 최신 GPU에서의 추론 성능을 보여주는 벤치마크 트윗이다.
金のニワトリ (@gosrum)
RTX 5090 환경에서 Nemotron-Cascade-2-30B-A3B(Q4_K_M)의 llama-bench 결과를 공유했다. prefill은 약 13000 tps, decord는 약 285 tps로, 최신 GPU에서의 추론 성능을 보여주는 벤치마크 트윗이다.
金のニワトリ (@gosrum)
Qwen3.5의 여러 크기(0.8B, 2B, 4B, 9B, 모두 UD-Q4_K_XL)에 대한 llama-bench 결과(RTX5090)를 보고. 처리량: 0.8B prefill ~35000 tps / decord ~435 tps, 2B prefill ~26000 / decord ~360, 4B prefill ~13000 / decord ~213, 9B prefill ~9000 / decord ~163.
金のニワトリ (@gosrum)
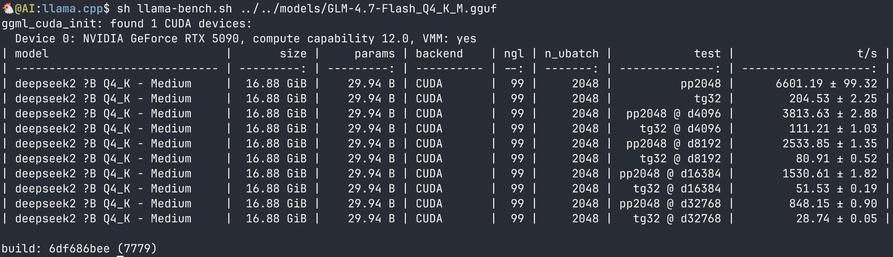
RTX5090에서 llama-bench로 GLM-4.7-flash의 추론 속도를 측정했더니, 의외로 flash-attn을 켜면 성능이 극도로 느려지는 현상이 확인되었다는 성능 이슈 보고입니다.
https://x.com/gosrum/status/2013415527675306048
#glm4.7flash #llamabench #rtx5090 #flashattn
Nvidia Jetson Orin Nano Super 8GB kiểm tra hiệu suất LLaMA #Nvidia #JetsonOrinNano #LLaMA #AI #TríTuệNhânTạo #ArtificialIntelligence #MachineLearning #LlamaBench
https://www.reddit.com/r/LocalLLaMA/comments/1oo88sq/nvidia_jetson_orin_nano_super_8_gb_llamabench/