Visiting an #LJC (London Java Community) meetup at #Hazelcast this eve. Looks interesting 😊.
Today, I've learned that the #Hazelcast project no longer provides patch releases for their community edition.
The rationale given is 'focus', or, paraphrased, to be able to give more attention to paying customers.
It appears that now, patch releases (mostly: bug fixes) do exist (I've seen release notes/changelogs), but are not published.
It is hard for me to come to terms with them deliberately keeping bugs live. That's mind-boggling and quite disappointing to me.


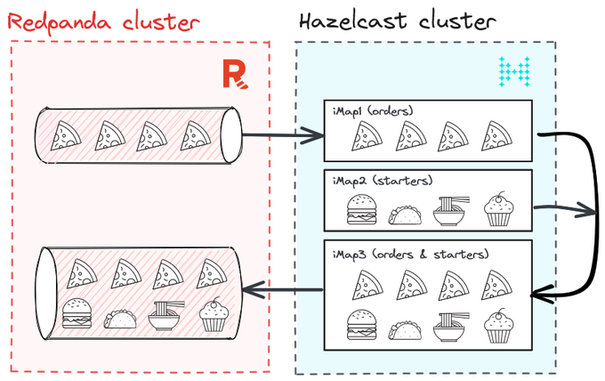



 Today!
Today!
