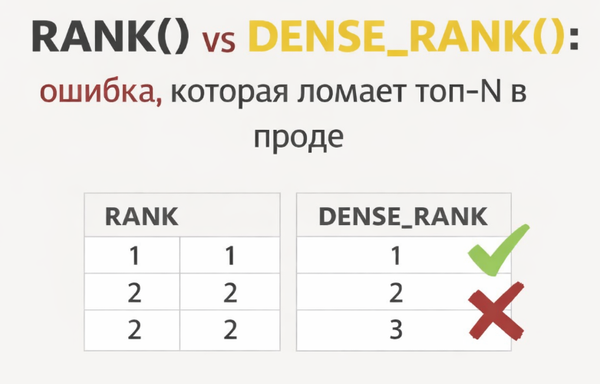
RANK() vs DENSE_RANK(): ошибка, которая ломает топ-N в проде
При работе с данными в SQL рано или поздно возникает задача ранжирования: топ-5 продуктов по продажам, рейтинг сотрудников по KPI, распределение клиентов по категориям. На первый взгляд RANK() и DENSE_RANK() делают почти одно и то же. На тестовых данных разница может быть вообще незаметна. Но в проде именно здесь часто начинаются ошибки: — топ-3 внезапно возвращает 5 строк; — дашборд "врёт"; — backend-логика начинает вести себя не так, как ожидалось; — запрос, который вчера работал быстро, сегодня уходит в disk spill. Две самые популярные функции для ранжирования — RANK() и DENSE_RANK() . Ниже разберём, чем они отличаются, где именно ошибаются разработчики и аналитики, и что важно понимать: не только что делает оконная функция, но и сколько она стоит на больших объёмах данных.
https://habr.com/ru/articles/1021094/
#sql #rank #dense_rank #window_functions #postgresql #оптимизация #производительность #аналитика #базы_данных #topn