My poster at #biodata22
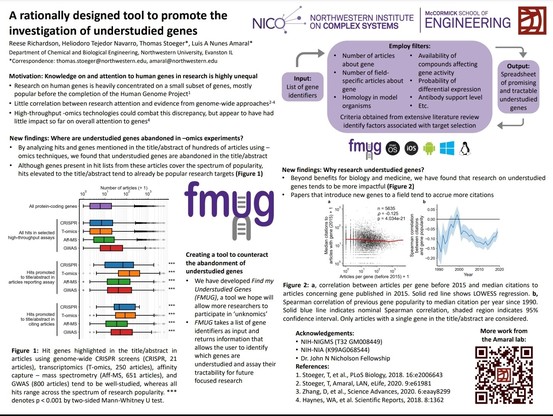
Short thread on my poster from #biodata22 on detecting allelic imbalance at isoform-level and in single cells, work with Rob Patro, Noor Singh, Euphy Wu et al.
PDF here: https://www.dropbox.com/s/yjr0d4mndnozwmd/DATA_22_Love.pdf?dl=0
@timtriche yeah I’ve been manually cross posting.
At #biodata22 I found Twitter was easier to use, eg I want to quickly look up handles and draft posts / threads during sessions, mostly to promote work by Phd students. Both of those are hard to do here (the latter not possible w the main app).
But for me this is week 1 of trying a new thing, entirely OSS and hosted/moderated by volunteers so I’ve got lots of patience to figure things out
That's a wrap on #biodata22, next one is #biodata24 on November 6-9, 2024.
Wish I could've attended in person this year, but a quick shout out to all the organizers who enabled a quick pivot to virtual! You da real MVPs!
Markus Sommer #biodata22 closing us out with "Structure‐guided isoform analysis for the human transcriptome".
Problem: We have many more transcript annotations than genes. Which isoforms actually represent functional proteins?
Leveraging folding algorithms (e.g. AlphaFold2) to score each isoform, high score = more likely to be functional. Showed some examples where this scoring approach matches experimental data. Says not perfect, but helpful data point.
Website: https://www.isoform.io/
Harun Mustafa #biodata22 on "A modular multi‐label framework for aligning sequences to large read set databases and (pan)genomes".
Problem: Low-coverage pan-sample (or genome?) alignment is challenging due to gaps in graphs (both sequence and labels), leading to shorter alignments downstream.
Describing a method, "MetaGraph-MLA", that allows the aligner to leverage "similar" samples (i.e. without the gap) to increase alignment lengths.
Pre-print: https://www.biorxiv.org/content/10.1101/2022.11.04.514718v1
Katharine Jenike #biodata22 on "Establishing a Solanum pan‐genome to dissect dynamics of paralog evolution".
Building a pan-genome from Solanum, so far with 17 fully assembled genomes built via HiFi + hifiasm followed by scaffolding via HiC and Bionano. Assemblies are chromosome scale and then annotated.
Described "Panagram", a tool for visualizing the constructed pangenome and exploring unique sequence, synteny, etc.:
https://github.com/kjenike/Panagram
Robert Patro (@rob) #biodata22 on "Keeping k‐mers in check—Building fast, small, and composable indices based on the De Bruijn graph".
Problem: Reference indexing is challenging, as we add reference (e.g. pangenome), the index grows rapidly. How do we keep this reference small?
Suggests model that splits index into two "tables" allowing for modular implementations, isolating bottlenecks.
Two repos mentioned:
Piscem: https://github.com/COMBINE-lab/piscem
Pufferfish2: https://github.com/COMBINE-lab/pufferfish2




