Treating SparkContext as a control tower shifts how you think about Spark: not just as an API, but as the coordinator for your entire distributed engine.
Read More: https://zalt.me/blog/2026/05/sparkcontext-control-tower

Treating SparkContext as a control tower shifts how you think about Spark: not just as an API, but as the coordinator for your entire distributed engine.
Read More: https://zalt.me/blog/2026/05/sparkcontext-control-tower
AQE (Adaptive Query Execution) : adapte le plan d'exécution en temps réel
DPP (Dynamic Partition Pruning) : ne lit que les partitions utiles pendant une jointure
SPJ (Storage Partition Join) : évite le shuffle en utilisant le partitionnement existant
https://luminousmen.com/post/the-apache-spark-optimization-checklist/ (en)
Comment optimiser Apache Spark ?
1. Utiliser les API DataFrame / Dataset, pas RDD.
2. Filtrer tôt, filtrer fort.
3. Trouver le data skew.
4. Connaitre AQE, DPP, SPJ.
5. Regarder l'UI.
Join me Tuesday for my next Python Data Science & AI Full Throttle! https://deitel.com/PYDSFT
O'Reilly Media Pearson #deitel #python #machinelearning #deeplearning #NLP #datamining #ApacheSpark #BigData #IoT #GenAI

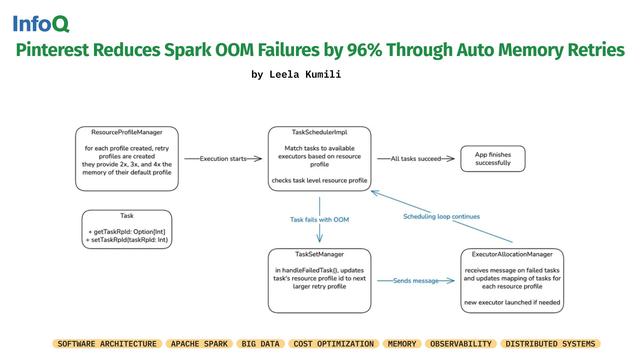
96% fewer out-of-memory (OOM) failures!
#Pinterest shared how it improved the reliability of its #ApacheSpark workloads.
By focusing on:
✅ Enhanced observability
✅ Configuration tuning
✅ Automatic memory retries
The changes addressed persistent job failures affecting recommendation systems and large-scale data processing.
Details here ⇨ https://bit.ly/4smqrQD
#SoftwareArchitecture #BigData #CostOptimization #Memory #DistributedSystems #Observability #InfoQ
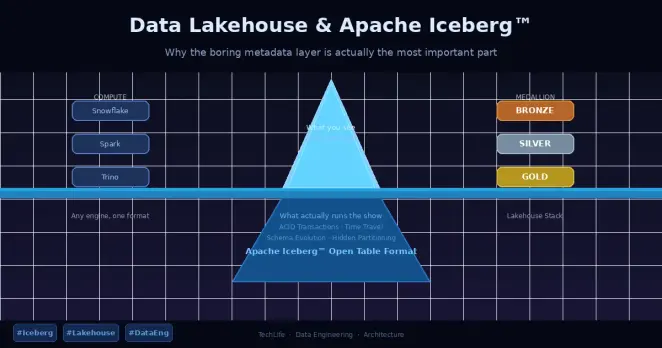
The Data Lakehouse Explained: Why Apache Iceberg Is Quietly Running the Show
https://techlife.blog/posts/data-lakehouse-iceberg
#ApacheIceberg #DataLakehouse #DataWarehouse #DataLake #Snowflake #ApacheSpark #DataEngineering
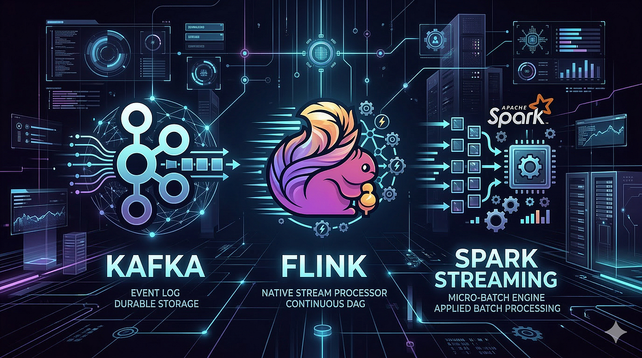
Kafka vs Flink vs Spark Streaming: What Nobody Tells You Before You Pick One
Bellevue / Seattle area friends: I’m super stoked for next week’s Spark Community Spring (Friday Mar 13th: spooky 👻).
If you’ve ever wanted to contribute to Apache Spark, come hang out and get your first Spark PR started with Felix Cheung, Huaxin Gao, Devin Petersohn, and myself :)
We’ll help folks find starter issues, get their dev environments set up, and walk through the contribution process.
There will be free lunch, and if enough people show up… maybe even Taco Bell for an afternoon snack*.
#ApacheSpark #OSS #hackathon #freelunch #tacofridaymaaaaybe
(* Depends on attendance)
#Pinterest launched a next-gen CDC-based ingestion framework.
Using #ApacheKafka, #ApacheFlink, #ApacheSpark & #ApacheIceberg, they achieved:
• Latency cut from 24+ hours to 15 minutes
• Processing of only changed records
• Support for incremental updates & deletions
• Petabyte-scale data across 1,000+ pipelines
Win: optimized cost & efficiency!
Read the architectural deep dive on InfoQ 👉 https://bit.ly/4rMJB2H

🚀 Big Data meets AI—powered by Iceberg, Spark & LLMs
At #ArcOfAI, Pratik Patel shows how to build a real architecture that lets users query massive datasets with natural language—no dashboards, no SQL, just questions & insights.
https://www.arcofai.com/speaker/1c241471d7f04018a0da70efffd35b32
🎟️ Get tickets: https://arcofai.com
#ArtificialIntelligence #BigData #DataArchitecture #ApacheSpark #ApacheIceberg #LLM #GenAI #EventStreaming #Kafka #Flink #AIEngineering #TechLeadership