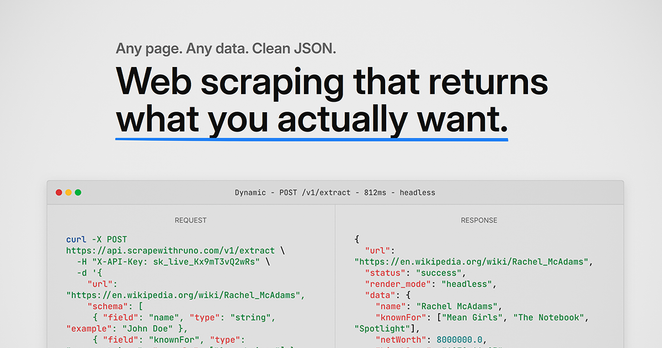
I built a Web-Scraper API that is 6-7x more efficient than current ones
#HackerNews #webscraper #API #efficiency #techinnovation #programming #tools
I built a Web-Scraper API that is 6-7x more efficient than current ones
#HackerNews #webscraper #API #efficiency #techinnovation #programming #tools
Cory – Blocking Countries because of scrapers
What the title says, Cory is blocking countries due to misbehaved scrapers. We do a bit of this at work, blocking misbehaving countries when they flood our sites with traffic. There is very little reason that anyone should be visiting the website of a city unless they live in the city, maybe the city next door, and maybe the originating country of the city.
99% of the time when a site gets DDOSed by something it’s coming from somewhere outside the country. The leading countries are India, China and North Korea. Sure a single person, or a family could be researching a city, but that doesn’t explain the traffic floods.
Many of our customers use Cloudflare so we just block them at the Cloudflare level and call it a day. I go back after a few weeks and remove the block because some valid traffic is reasonable.
I had to take a line like that on my own site as well, block a bunch of offending scrapers and bots from countries. It sucks to stop regular people from visiting my site but I’ve already dealt with a bill of $5k in a month that should have been $50 and I don’t need another one.
#webCrawler #webScraperBright Data’s new API lets developers weave AI/ML models, LLMs and generative AI directly into web‑scraping workflows while keeping bots at bay. JavaScript‑ready, open‑source friendly, and built for seamless anti‑bot protection. Dive into the benchmarks and see how it powers smarter data pipelines. #BrightDataAPI #AIintegration #AntiBot #WebScraper
🔗 https://aidailypost.com/news/bright-data-api-delivers-seamless-aiml-integration-antibot-protection

🔍 / #software / #automation / #scraping
#WebScraper - The #1 web scraping extension
The most popular web scraping extension. Start scraping in minutes. Automate your tasks with our Cloud Scraper. No software to download, no coding needed.
Tìm kiếm web không cần OpenWebUI? Thử MCP server với Jan để scraper ddgs hoặc quantized models với llama.cpp #TìmKiếmWeb #WebSearch #OpenWebUI #LLaMA #AI #MCP #Jan #QuantizedModels #LlamaCpp #TrợGiúp #HỗTrợ #AItools #WebScraper #TìmKiếmTrựcTuyến #CôngCụTìmKiếm #TrangWeb #TìmKiếmNhanh
https://www.reddit.com/r/LocalLLaMA/comments/1os0xwn/how_to_get_web_search_without_openwebui/
🤖 Ottenere l'elenco di tutte le immagini di una pagina HTML con PHP
Sviluppare un web scraper con PHP per ottenere l'elenco completo di tutte le immagini di un url...
8 Web Scraping & Crawling Tools mit n8n-Anbindung (Workflow-Vorlage zum kostenlosen Download)
Wir schauen uns heute an, wie ihr Web Scraping und Crawling betreiben könnt. Dazu schauen wir uns 8 verschiedene Tools an und verbinden diese auch direkt mit n8n, damit ihr die extrahierten Daten in einem Workflow weiter verarbeiten könnt.
https://www.youtube.com/watch?v=LP571gnIg7A
#n8n #ki #automatisierung #webscraping #webcrawler #webscraper

3/
For more on scraping (as in web-scraping) see here:
https://mastodon.social/@reiver/114353728684249608
CC: @404mediaco