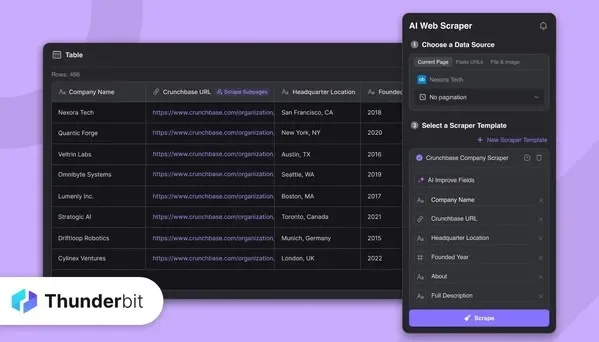
Thunderbit Rolls Out New Tools For Web Data Sifting
Thunderbit launched new tools like an API and CLI to help developers turn web page content into usable data for AI and automation. Learn how it works.
#WebData, #DeveloperTools, #AI, #DataExtraction, #Thunderbit
https://newsletter.tf/thunderbit-new-tools-for-developers-web-data/