Why removing 'um' from a recording is harder than it sounds
https://doug.sh/posts/erm-a-local-cli-that-strips-ums-uhs-and-erms-from-speech/
Why removing 'um' from a recording is harder than it sounds
https://doug.sh/posts/erm-a-local-cli-that-strips-ums-uhs-and-erms-from-speech/
𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗮𝘁 𝗨𝗜𝗼𝘄𝗮: 𝗥𝗲𝗳𝗶𝗻𝗶𝗻𝗴 𝗛𝗼𝘄 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 𝗣𝗿𝗼𝗰𝗲𝘀𝘀 𝗔𝘂𝗱𝗶𝗼
Weiran Wang has defined his career by exploring machine learning and speech processing. 💬
Google DeepMind is helping fund his personal research on advancing audio comprehension within Large Language Models. 💻
“By preventing phantom narratives and limiting AI’s responses to facts present in the audio, the reliability of models increases.”
Read at https://cs.uiowa.edu/news/2026/04/ai-research-uiowa-refining-how-large-language-models-process-audio !

Basically, non-blackbox interpretive AI seems a lot more useful than generative AI from a “let’s not destroy the world” standpoint
#AI #generativeAI #interpretiveAI #tokenization #blackbox #nonblackbox #savesocial #SaveTheUS #kanji #grammar #speech #speechprocessing #languages #language #LLM #dialectrecognition #SaveTheWorld #mediapreservation
Speech and Language Processing (3rd ed. draft)
https://web.stanford.edu/~jurafsky/slp3/
#HackerNews #SpeechProcessing #LanguageProcessing #NLP #StanfordJurafsky #DraftEdition

We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.

A new study finds that the left posterior inferior frontal cortex activates within 100 milliseconds during reading, playing a critical, early role in turning text into speech, challenging traditional models that assumed a slower, step-by-step process.


Human-to-pet communication requires speech processing by the animal and adjustments of the human speaking rate to match their pet’s receptive abilities. This study shows that dogs and humans share similar but not identical speech processing mechanisms and that dog-human vocal interactions match dogs’ sensory-motor tuning.

Apply for a fully funded PhD position now! Topics in my team range from privacy in speech processing, speech enhancement and low-resource speech processing to…
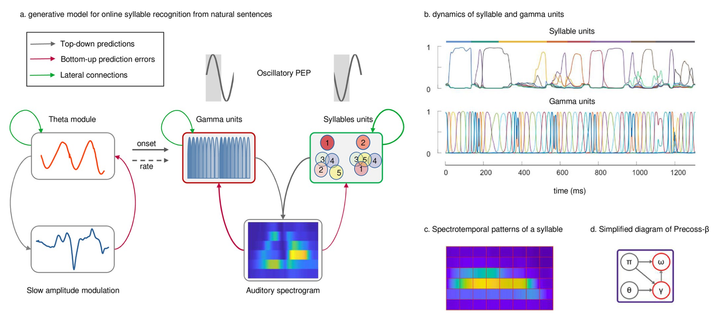
Rhythmic modulation of prediction errors: A top-down gating role for the beta-range in #speechprocessing – new work by Hovsepyan et al. (2023).
🌍 journals.plos.org/ploscompbiol/a…