"TiAb Review Plugin: A Browser-Based Tool for AI-Assisted Title and Abstract Screening"
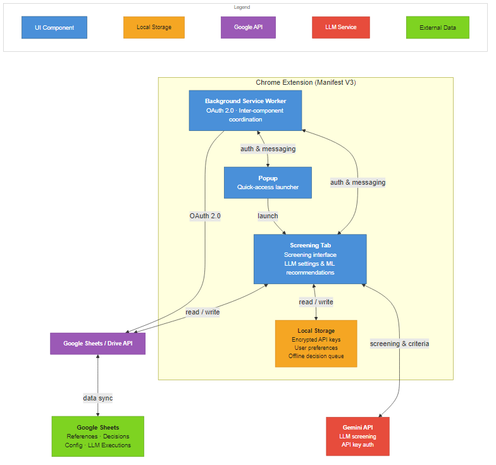
TiAb Review Plugin is an open-source Chrome browser extension (available at this https://chromewebstore.google.com/detail/tiab-review-plugin/alejlnlfflogpnabpbplmnojgoeeabij URL). It uses Google Sheets as a shared database, requiring no dedicated server and enabling multi-reviewer collaboration. Users supply their own Gemini API key, stored locally and encrypted.