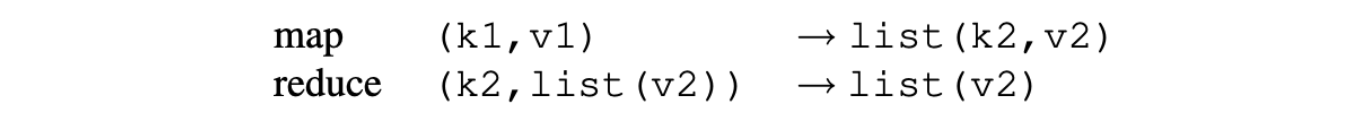🚀✨ Behold, the thrilling tale of querying 3 billion vectors—a journey where Vicki Boykis heroically attempts to decode Jeff Dean's cryptic wisdom on #mapreduce. Spoiler: It's basically a nerdy treasure hunt for semantically similar items, but with more floating-point numbers than your brain can handle. 💻🧠
https://vickiboykis.com/2026/02/21/querying-3-billion-vectors/ #HackerNews #VickiBoykis #treasureHunt #techJourney #floatingPoint #HackerNews #ngated
https://vickiboykis.com/2026/02/21/querying-3-billion-vectors/ #HackerNews #VickiBoykis #treasureHunt #techJourney #floatingPoint #HackerNews #ngated