Быстро — не всегда хорошо: рейтлимиты в мультикластерном окружении
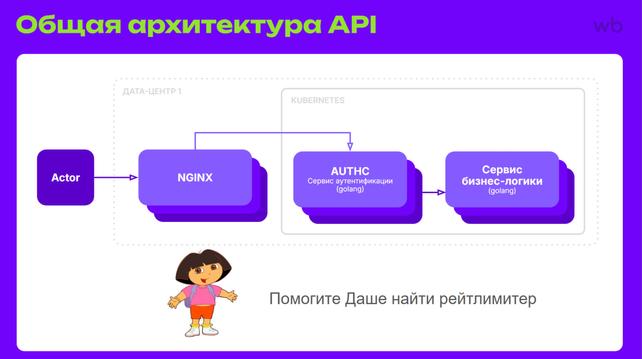
Всем привет! Кажется, настало время поговорить о том, как внедрялись ограничители частоты запросов на бэкенд в Wildberries. В статье — о том, с какими трудностями мы столкнулись на этом благородном пути и как прошли через четыре схемы реализации — от простейшей in-memory до собственных gRPC-сервисов. Не обойдём вниманием и парочку лайфхаков ;) Например, с помощью рейтлимитов мы неожиданно решили проблему плавного отключения старых версий API. Меня зовут Дмитрий Виноградов , и я лид команды публичного API Wildberries. До этого почти 18 лет занимался промышленной автоматизацией в Schneider Electric — от программирования контроллеров и embedded-устройств до собственных SCADA-систем. Хочешь не хочешь, а научишься делать красивые интерфейсы :)
https://habr.com/ru/companies/wildberries/articles/932050/
#redis #go #rate_limiting #api #распределенные_системы #grpc