There is a cool feature in llama.cpp to "parse PDF as image" rather than text. You will need to enable it, and reattach the document for a multimodal LLM like Gemma4 26B A4B to analyze it.
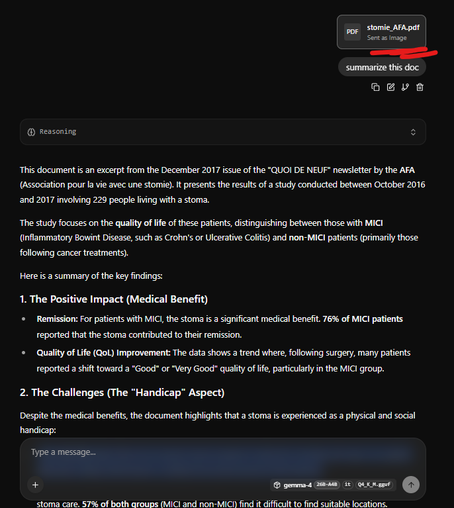
Here for example a doc by the AFA (Association pour la vie avec une stomie) on ileostomy from 2017 in French: there are pictures in it which cannot be vectorized I think (and thereof be used in a #RAG). #Gemma4 26B A4B can translate it to English.✅
#ileostomy #MICI #stomie #iléostomie
(link to doc in ALT)