#AMD threatens to go medieval on Nvidia with #Epyc and #Instinct: What we know so far
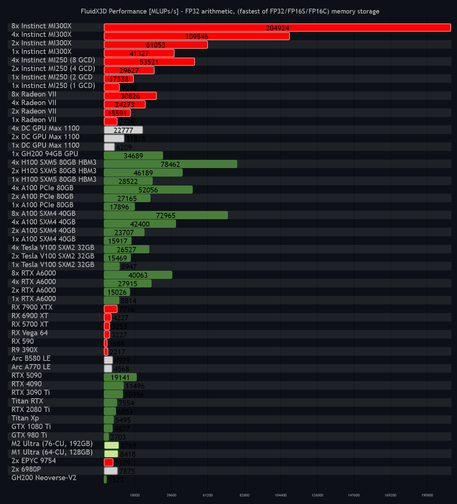
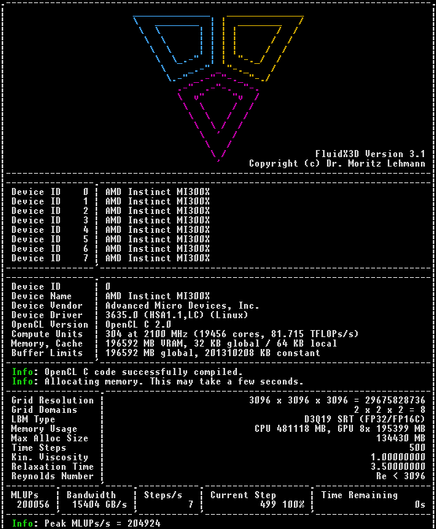
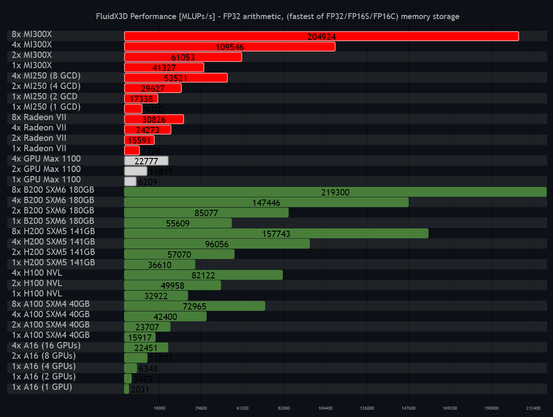
AMD teased its next-generation #AI accelerators at #CES2026, with CEO Lisa Su boasting the #MI500-series will deliver a 1,000x uplift in performance over its two-year-old #MI300X #GPU.
if AMD wants to stay competitive with Nvidia, MI500-series will need to deliver performance on par with if not better than Rubin Ultra Kyber racks.
AMD joins the #rackscale race with #MI455X #Helios racks.
https://www.theregister.com/2026/01/07/mi500x_amd_ai/
AMD teased its next-generation #AI accelerators at #CES2026, with CEO Lisa Su boasting the #MI500-series will deliver a 1,000x uplift in performance over its two-year-old #MI300X #GPU.
if AMD wants to stay competitive with Nvidia, MI500-series will need to deliver performance on par with if not better than Rubin Ultra Kyber racks.
AMD joins the #rackscale race with #MI455X #Helios racks.
https://www.theregister.com/2026/01/07/mi500x_amd_ai/



 Hacker News
Hacker News