Wie Gemini (fast) perfekte Transkriptionen liefert
Googles Sprachmodell Gemini hat nach einem schwachen Start zugelegt. Doch in meinen Vergleichstests schneidet die Konkurrenz weiterhin besser ab. ChatGPT, Claude, Perplexity, Mistral Le Chat und Deepseek sind durch die Bank informativer und prägnanter.
Doch neuerdings gibt es einen stichhaltigen Grund, Gemini zu verwenden – zumindest für einen spezifischen Zweck. Seit Mitte September beherrscht Googles Sprachmodell die Transkription. Es transkribiert (wie hier besprochen) Videoanrufe und -konferenzen via Google Meet. Es verschriftlicht auch hochgeladene Audiodateien und liefert ein Transkript nach Mass. Das heisst, wir können im Prompt angeben, worauf besonders geachtet werden soll.
Für einen Test verwende ich einige Aufnahmen in verschiedenen Sprachen und Aufnahmequalitäten, die schon bei früheren Gelegenheiten zum Einsatz kamen. Dadurch lassen sich die Resultate hervorragend vergleichen, namentlich mit Trint, Descript, Töggl, Whisper, Happy Scribe und Swiss Transcribe. Allerdings mit dem wichtigen Disclaimer, dass die Tests der weiteren Anwendungen vor einiger Zeit durchgeführt wurden. Es ist denkbar, dass sie einige der älteren Kandidaten inzwischen verbessert haben.
Auch unter schwierigen Umständen liefert Gemini ein brauchbares Resultat
Die fünf Beispiele¹ zeigen, dass Gemini kein rundum perfektes Resultat abliefert, aber unter idealen Umständen einen verständlichen, brauchbaren Text produziert. Im Vergleich zu den Ergebnissen, die ich vor zwei Jahren dokumentierte, bedeutet Gemini einen Sprung nach vorn. Das sind meine Beobachtungen im Detail:
- Mein Eindruck ist, dass diese Transkription von Gemini weniger unter einer schlechten Tonqualität leidet, als das früher der Fall war. Ich vermute, dass Google die Software intensiv mit Mitschnitten von Google Meet trainiert und sich das bezahlt macht.
- Die Schweizer Mundart und ein exotisches Vokabular sind nach wie vor die grösste Hürde. Dennoch sind auch die Dialekt-Passagen weitgehend verständlich.
- Das Interview in Englisch ist fehlerfrei, ebenso das Telefoninterview in Hochdeutsch.
- Beim Telefoninterview in Schweizerdeutsch scheint die KI einzelne Begriffe nicht oder missverstanden zu haben, was zu einer Fehlinterpretation eines Satzes oder Abschnitts führt.
- Meine Rezitation von «Babette von Interlaken» hat eine vom Schweizerdeutschen beeinflusste Satzstellung. Sie ist grammatikalisch oft ungehobelt oder falsch und unschön zu lesen. Dennoch ist das Transkript fast so gut wie das der auf Schweizerdeutsch getrimmten Software Swisstranscribe.
Wie gewünscht, transkribiert Gemini den Text und gliedert ihn passend in Abschnitte.
Das Fazit fällt entsprechend erfreulich aus: Wenn wir die Transkription nur sporadisch verwenden und (z. B. über unseren Arbeitgeber) Zugang zu Google Workspace haben, dann können wir uns eine separate Transkriptions-Anwendung in vielen Fällen sparen. Eine Anwendung wie Happy Scribe ist allerdings nach wie vor sinnvoll für die Nachbearbeitung: Sie stellt einen Editor zur Verfügung, mit dem sich die Passagen im Original anhören und verbessern oder redigieren lassen – diese Möglichkeit bietet Gemini nicht.
Gemini transkribiert nah am Original-Wortlaut
Bemerkenswert an der Transkription von Gemini sind ferner die folgenden Dinge:
- Anders als andere Anwendungen unterscheidet Google nicht zwischen den Sprechern. Die Software hat auch oft Mühe dabei, einen Sprecherwechsel zu erkennen. Sowohl beim Interview in Englisch als auch beim Gespräch in Hoch- und Schweizerdeutsch wurden Aussagen zu einzelnen Sätzen zusammengeführt, die im Original von verschiedenen Personen stammen – das ist nachteilig für die Verständlichkeit.
- Gemini transkribiert nah am ursprünglichen Wortlaut; wie die Beispiele unten zeigen, sind in der Verschriftlichung viele «Ähs» enthalten, ebenso Füllwörter und -phrasen wie «also», «so», «quasi», «glaube ich», «irgendwie» und so weiter.
Letzteres führt zu schwer lesbaren Transkripten. Trotzdem begrüsse ich es, wenn das Sprachmodell von sich aus möglichst wenig an den Texten ändert und möglichst originalgetreu arbeitet – ich hätte nichts dagegen, wenn die Mundart-Quellen in Mundart und nicht in einem Pseudo-Hochdeutsch verschriftlicht würden.
Auch die Nachbearbeitung übernimmt die KI
Natürlich ist die künstliche Intelligenz gern bereit, das Transkript in eine flüssiger lesbare Form zu überführen. Ich verwende dafür folgenden Prompt:
Kannst du mir das Transkript straffen, d. h., Redundanzen und typische Artefakte der mündlichen Rede entfernen, umgangssprachliche Redewendungen verschriftlichen, Ähs und Füllwörter weglassen? Achte aber darauf, inhaltlich nichts wegzulassen und keine Bedeutungsveränderungen vorzunehmen!
Ein abschliessender Vorteil besteht darin, dass wir eine echte Alternative zu den gängigen Transkriptionslösungen bekommen. Die basieren in aller Regel auf Whisper, der Open-Source-Software von OpenAI. Das führt dazu, dass sich viele der abgeleiteten Produkte wie Happy Scribe, Swiss Transcribe und Töggl in den Resultaten ähneln. Google setzt (soweit ich das beurteilen kann) auf eine eigene Technologie.
ChatGPT führt Transkripte von zwei separaten KIs zu einem Text zusammen und markiert Unstimmigkeiten.
Trick 77 für die Fehlersuche
Daraus ergibt sich eine vielversprechende Möglichkeit für hervorragende Transkripte: Wir lassen uns die gleiche Aufnahme separat z. B. von Swiss Transcribe und Gemini transkribieren. Dann bitten wir eine unbeteiligte KI, uns eine konsolidierte Fassung zu erstellen. Ich habe diesen Auftrag ChatGPT erteilt – mit folgendem Prompt:
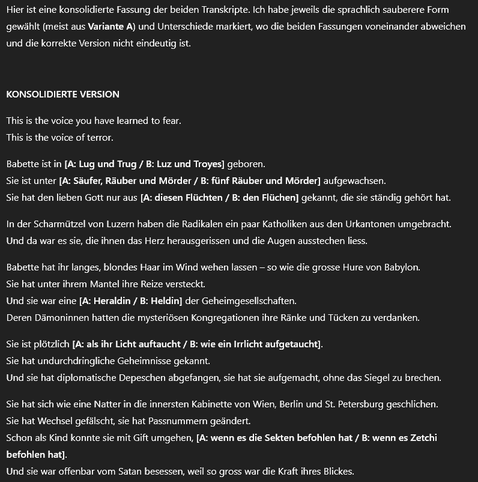
Ich habe nachfolgend die gleiche Audioaufnahme, von zwei separaten Transkriptionslösungen verschriftlichen lassen. Bitte führe sie mir zu einer konsolidierten Fassung zusammen: Verwende jeweils die schönere sprachliche Formulierung und markiere jene Stellen, bei denen sich die Transkripte unterscheiden und du nicht sicherstellen kannst, ob eine der beiden Varianten korrekt ist.
Ich habe das mit «Babette von Interlaken» ausprobiert: Sprachlich ist auch die konsolidierte Fassung nicht über alle Zweifel erhaben. Aber die Stellen, in denen sich die Transkripte unterscheiden und die manuell überprüft werden müssen, hebt ChatGPT ausgezeichnet hervor. Mit dieser Methode traten Fehler zum Vorschein, die ich selbst übersehen hatte …
Nachtrag: Achtung bei langen Aufnahmen
Eine wichtige Einschränkung ist mir erst nach Veröffentlichung dieses Blogposts aufgefallen. Gemini transkribiert nicht beliebig lange Aufnahmen. Bei Podcasts ab ungefähr 45 Minuten stellte ich fest, das Teile fehlen – und zwar nicht unbedingt am Ende, sondern mittendrin. Das ist tückisch – daher der Ratschlag, wichtige Aufnahmen dennoch mit einem dedizierten Transkriptionstool zu bearbeiten oder Gemini anzuweisen, explizit darauf hinzuweisen, wenn ein Transkript unvollständig ausfällt. Alternativ kann man sich auch Zeitmarken angeben, die (vielleicht) helfen, Lücken aufzuspüren.
Es gibt auch gute Nachrichten: Gemini ist grossartig darin, Sprecher und Sprecherinnen zu erkennen und mit Namen zu beschriften, und selbst Dinge wie Musik, Geräusche und Athmo zu benennen.
Fussnoten
1) Hier sämtliche Tests im Original-Wortlaut:
Telefoninterview Schweizerdeutsch
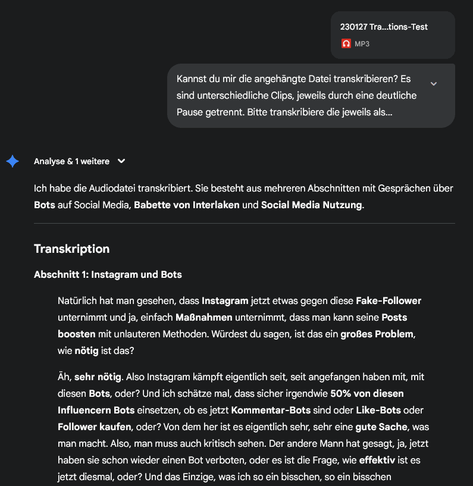
Natürlich hat man gesehen, dass Instagram jetzt etwas gegen diese Fake-Follower unternimmt und ja, einfach Massnahmen unternimmt, dass man kann seine Posts boosten mit unlauteren Methoden. Würdest du sagen, ist das ein grosses Problem, wie nötig ist das?
Äh, sehr nötig. Also Instagram kämpft eigentlich seit, seit angefangen haben mit, mit diesen Bots, oder? Und ich schätze mal, dass sicher irgendwie 50% von diesen Influencern Bots einsetzen, ob es jetzt Kommentar-Bots sind oder Like-Bots oder Follower kaufen, oder? Von dem her ist es eigentlich sehr, sehr eine gute Sache, was man macht. Also, man muss auch kritisch sehen. Der andere Mann hat gesagt, ja, jetzt haben sie schon wieder einen Bot verboten, oder es ist die Frage, wie effektiv ist es jetzt diesmal, oder? Und das Einzige, was ich so ein bisschen, so ein bisschen hoffnungserweckend gesehen habe, ist halt, dass sie jetzt halt mit KI einsetzen, äh, dass sie halt die Bösebuben identifizieren können, oder? Und dass sie dann natürlich auch die User informieren, hey, ähm, wir haben dir irgendwie Leute rausgeschmissen oder äh, da war so ein bisschen Stillschweigen gewesen. Er hat so Shadow Ban gesagt, oder? Dass Instagram dich praktisch bestraft, aber du hast nicht gewusst, wieso.
Und jetzt quasi muss man auch damit rechnen, dass es öffentlich wird, wenn man, wenn man erwischt wird, quasi.
Also, öffentlich wird es, glaube ich, nicht. Das so, was ich verstanden habe, kriegst du so eine In-App Message, so eine Notification über von Instagram, dass sie das entdeckt haben. Ähm, ich glaube nicht, dass sie es öffentlich machen. Das kannst du dann irgendwie ja, aber wäre es denn aus deiner Sicht sinnvoll, wenn man, wenn man eben würde Leute auch anprangern, wo da quasi bescheissen? Genau, würde, würde aus deiner Sicht sinnvoll wenn man die Leute tatsächlich würde anprangern, wenn man, wenn man könnte beim Bescheissen erwischt werden?
Telefoninterview Hochdeutsch
Ich starte mal ganz profan mit der Frage, was ist ein Bot?
Ja, was ist ein Bot? So profan ist die Frage schon gar nicht. Also, das, äh, der Begriff Bots kommt von Roboter, Robot, und, ähm, eigentlich sind damit schon zwei unterschiedliche Sachen gemeint, nämlich, äh, der klassische Begriff eines Bots. Es gab auch früher schon sowas wie Bot-Netze. Damit war eigentlich gemeint, dass, äh, dass Computer durch Schadsoftware selbstständig agieren. Also, äh, das heisst, wir hatten Viren, die sich verbreitet haben und dann auf Ihrem Rechner und meinem Rechner und sonst wo, äh, plötzlich die Rechner autonom angefangen haben zu agieren und vielleicht Spam versandt haben, ohne dass wir das überhaupt mitgekriegt haben. Genau. Das, das waren eigentlich diese, äh, daher kommt eigentlich der, der Begriff dieser Bot-Netze. Jetzt gibt’s dann, ähm, aber eben durch Social Media einen Bezug dazu, äh, wo eben auf der einen Seite die sogenannten Social Bots oder naja, vielleicht erstmal so insgesamt alle, alle Programme, äh, auf Social Media, die irgendwie, ähm, autonom agieren, werden als Bots bezeichnet. Mhm. Und da gibt’s dann noch mal die Unterscheidung zwischen Bots, die sich auch als Bots zu erkennen geben, das ist das, worüber Facebook jetzt zum Beispiel redet, wenn die das Zeitalter der Bots ausrufen, und, äh, solche, die so tun, als wären sie echte Menschen. Und das wären dann Social Bots.
Begegnen wir, äh, diesen Bots heute schon?
Ja, und zwar, ähm, zum Beispiel, ähm, Siri ist ein, ein Bot oder auch, äh, wenn ich an meinem Android-Phone «Okay Google» sage, dann ist ja dahinter ein Bot, äh, in dem Sinne, dass ich halt autonom agierende Software habe, mit der ich dann kommunizieren kann.
Interview in Englisch
You know, I talked with Matthias Kirchner, I guess the name from Free Software Foundation Europe for the radio show I was telling you about and then I played your Free Software song on the show.
Yeah. There are lots of interpretations from lots of bands.
Yes, and that’s an example of a filk song. Have you heard the term filk song?
Filk?
Yes, f-i-l-k. No, if you look up filk songs, if you search for it, you’ll find lots of amusing songs and some that are not amusing. But in any case, I was at a science fiction convention. I was at a filk singing meeting, which was operating by what they call Bardic circle, which means they go around the room and each person has a chance to either sing or request that someone else sing something. And I had just sung something and there were at least 20 people in the room, so I knew that would be a long time before I had another chance. I decided to write a song. But since I was not starting from an inspiration, I had to come up with a topic. I thought, why not write about free software? Right? I’ve never written anything about that. And then since I had no inspiration, I had to come up with a tune. I thought, why not use a Balkan dance tune? Which one? Well, Sadi Moma suggested itself because it’s very beautiful and not too fast.
Interview Hochdeutsch/Schweizerdeutsch
Welche nutzt du, welche Plattformen jetzt mehr oder weniger aktiv im Moment, weisst du es?
Ähm, ja, also, ich glaube, ich bin am aktivsten noch auf Instagram. Da haben wir ja vor einem Jahr oder so, glaube ich, schon mal die die Klingen gekreuzt, weil wir unterschiedlicher Meinung waren in in Punto Instagram. Ähm, da hat sich allerdings bei mir in den letzten Monaten so ein bisschen das verändert, dass ich tatsächlich mehr passiv konsumiere als wirklich aktiv bin auch. Ähm, und sonst, ich nutze Linkedin nicht mit Begeisterung, aber so aus so einer Jobnotwendigkeit her. Und ähm, bei Twitter ist es für mich so ein bisschen ein Auf und Ab. Da da kommt es sehr auf die Tagesform an, aber äh ich bin da früher sehr viel aktiver gewesen auch.
Genau, der Instagram-Krach, Krach ist ein bisschen viel gesagt, aber wir sind einfach unterschiedlicher Meinung gewesen. Ich habe schon dort gefunden, es hat sich so verschoben das Gleichgewicht auch, von so quasi Kommunikation auf Augenhöhe hin zu eben Influencer versus du bist halt der Kleine, wo, wo auch irgendwie kann irgendein Post posten. Und dann ist es ein super Foto, wenn ich finde, aber du kommst drei Herzli oder so, also vier vielleicht, weil, weil, weil es wirklich sensationell ist. Und darum habe ich dort ein bisschen das Interesse verloren. Ich habe auch noch schnell gekuckt, wie viel, dass das sind. Ich habe zehn, ich bin auf zehn gekommen, wo ich nutze mehr oder weniger aktiv im Moment. Aber man sieht dann schon auch, welche das werden sterben wieder von denen. Also Twitter, Facebook, ich glaube, am meisten Twitter und dann Facebook, Linkedin, naja, ein bisschen Untappd, das, das Bier Social…
Da bin ich auch sehr aktiv, das ist richtig. Aber das ist mehr, das ist ja nicht so sehr zum Interagieren, sondern das ist für mich zumindest mehr so zum selber dokumentieren, äh, wie, wie schlecht war das Feldschlösschen jetzt wirklich.
Rezitation in Schweizerdeutsch
This is the voice you have learned to fear. This is the voice of terror.
Babette ist in Luz und Troyes geboren. Sie ist unter fünf Räuber und Mörder aufgewachsen. Sie hat den liebevollen Gott nur aus den Flüchen gekannt, wo sie ständig gehört hat. In der Scharmützel von Luzern haben die Radikale ein paar Katholiken aus der Urkantone umgebracht und da ist sie es gewesen, wo ihnen das Herz ausgerissen und die Augen ausstechen liess. Babette hat ihr langes blondes Haar im Wind wehen lassen, so wie die grosse Hure von Babylon. Sie hat unter ihrem Mantel ihre Reize versteckt und sie ist eine Heldin von der Geheimgesellschaft gewesen. Deren Dämonen haben die mysteriöse Kongregationen ihre Ränke und Tücken zu verdanken gehabt. Sie ist plötzlich wie ein Irrlicht aufgetaucht. Sie hat undurchdringliche Geheimnisse gekannt und sie hat diplomatische Depeschen abgefangen. Sie hat sie aufgemacht, ohne das Siegel zu brechen. Sie hat sich wie eine Natter in die innerste Kabinette von Wien, von Berlin und von Sankt Petersburg geschlichen. Sie hat Wechsel gefälscht. Sie hat Passnummern geändert. Als Kind hat sie können mit Gift umgehen, wenn es Zetchi befohlen hat. Und sie ist offenbar vom Satan besessen gewesen, weil so gross ist die Kraft von ihrem Blick gewesen.
Babette von Interlaken, so heisst die Frau, wo der Umberto Eco da beschrieben hat. Er als Semiologe hat sich mit den Zeichen beschäftigt und ihre Deutung ausgekannt. Er hat in seinem berühmten Roman die verschwörerische Kraft von der Religion beschrieben und er hat in seinem Buch Der Friedhof in Prag von 2010 eindrücklich aufgezeigt, wie aus antisemitische Vorurteil dann der Judenhass wird und eine von der grässlichsten Verschwörungstheorien überhaupt. In dem Buch da kommt aber eben auch die Babette von Interlaken vor, die häre Jungfrau vom Schweizer Kommunismus. Sie sei dem Eco im Traum erschienen, schreibt er, wenn er in ihrem Halbschlaf das Bild von der blonde Dämonin mit ihrem wehrenden Haar auf der sicherlich blutigen Schulter habe wollen verscheuchen. Das dämonisch lockende Irrlicht mit vorsündiger Wollust bebenden Busen ist sie ihm als Modell zur Nachahmung vorgeschwebt. Das Internet, Wikipedia und die üblichen Quellen wissen nichts über die Babette von Interlaken. Der Eco wirklich vermutet, es handle sich um die Geschichte der Eisenjungfrau vom Hans Christian Andersen. Dort ist Babette allerdings eine Walliserin und weniger Intrigantin und Dämonin als vielmehr eine liebenswerte Frau, wo dem Held von der Geschichte den Kopf verdreht. Der Protagonist von der Eisenjungfrau lädt sich als luftigere Variante vom Schweizer Nationalheld verstehen, hat der Tagi geschrieben, als Tell mit dem Andersen-Herz. Mit anderen Worten, der Eco liegt mit seiner Vermutung völlig daneben und kommt überhaupt nicht drauf. Aber die NZZ die hat in ihrer fast 240-jährigen Geschichte ein einziges Mal über die Babette von Interlaken geschrieben, am 29. März 1881 hat’s wie folgt geheissen: Es ist die berüchtigte Babette gewesen, die merkwürdige Urenkelin vom Weishaupt. Weishaupt übrigens der Gründer von der Illuminati, wenn ich darf anführen. Der Pfarrer Weyermann hat sie die grosse Jungfrau vom Kommunismus genannt und dann kommt fast wortwörtlich das Zitat vom Umberto Eco. Die Babette hat den Katholiken das Herz oder die Eingeweide ausgerissen und dafür hat Babette ein Batzen und ein Glas Kirschwasser überkommen. Die Babette hat 1846 für die erste Regierungsräte vom Kanton Bern der Funker, der Ochsenbein und der Stockmar und Konsorte Vermittlungsaufgaben übernommen. Sie hat geflucht wie ein Radikaler, gesoffen wie ein Aargauer und geraucht wie ein Türk, heisst es in der NZZ. Und damit wird die Sache ein bisschen klarer. Babette ist im Sonderbundskrieg auf der Seite von der Eidgenossenschaft gestanden. Sie hat gegen die katholische Kantone in der Innerschweiz gekämpft, wo nichts vom Bundesstaat haben wollen wissen. Der Text in der NZZ ist eine Kritik vom Buch Der Jude von Verona gewesen, 1859 rausgekommen, in der Buchhandlung Hurter von Schaffhausen. Der Autor von dem Buch hat die NZZ nicht rausgefunden, aber wir wissen heute, dass es der Antonio Bresciani gewesen ist. Der hat sich als Schriftsteller auf die Seite von der Katholiken geschlagen und die NZZ schreibt dann auch, das Ziel von dem kuriose Buch sei, die Liberale mit Schimpf und Schande zu überschütten und abschliessend hat sich die NZZ gefragt, warum die Buchhandlung Hurter Schaffhausen so einen Schund überhaupt ausgibt. Und mir wissen jetzt also ein bisschen mehr über die Babette von Interlaken, das Rau-Bein, wo gesoffen hat wie ein Aargauer und offenbar so eine Art die Schweizer Mata Hari gewesen ist. ↩
Beitragsbild: Das waren noch Zeiten, als ich noch selbst abtippen musste!
#Gemini #KI #KIQuicktipp #Transkription