Steerling-8B, the first interpretable model that can trace any token it generates to its input context, concepts a human can understand, and its training data.
https://www.guidelabs.ai/post/steerling-8b-base-model-release/
Steerling-8B, the first interpretable model that can trace any token it generates to its input context, concepts a human can understand, and its training data.
https://www.guidelabs.ai/post/steerling-8b-base-model-release/
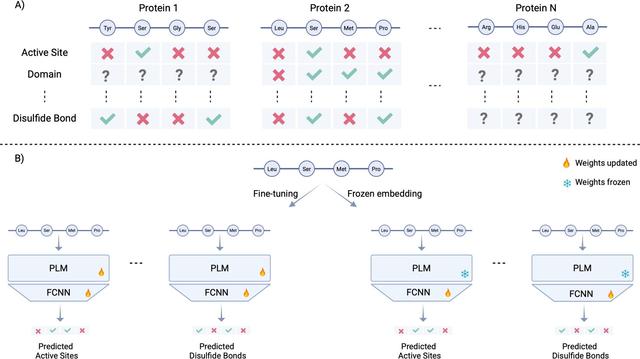
🤖 Are protein language models the next revolution in functional genomics?
🔗 Fine-tuning protein language models to understand the functional impact of missense variants. Computational and Structural Biotechnology Journal, DOI: https://doi.org/10.1016/j.csbj.2025.05.022
📚 CSBJ: https://www.csbj.org/
#Genomics #AI #ProteinLanguageModels #Bioinformatics #PrecisionMedicine #PLM #MissenseVariants #MachineLearning #ClinicalGenetics #AIinHealthcare #InterpretableAI #VariantInterpretation
🧠🤝 The 1st SemGenAge Workshop is now live at #ESWC2025!
📍 Room 5 – Adria II, Floor 11
SemGenAge is exploring how to bridge the gap between Large Language Models (LLMs) and Semantic Web technologies, with the goal of building intelligent agents that are interpretable, controllable, and socially aware.
Join us to shape the future of human-aligned, explainable AI! 🚀
#SemGenAge2025 #LLMs #SemanticWeb #IntelligentAgents #InterpretableAI #ResponsibleAI #KnowledgeGraphs #SocialAI #ESWC2025


🧠 Is AI ready to be your doctor’s second opinion — or is it still a black box?
🔗 From explainable to interpretable deep learning for natural language processing in healthcare: How far from reality?. Computational and Structural Biotechnology Journal, DOI: https://doi.org/10.1016/j.csbj.2024.05.004
📚 CSBJ Smart Hospital: https://www.csbj.org/smarthospital
#XIAI #ExplainableAI #InterpretableAI #HealthcareAI #NLPinHealthcare #Transformers #DeepLearning #ClinicalNLP #AIethics #MedicalAI #XAI #IAI
Understanding AI through the use of expressive Boolean formulas #InterpretableAI
Hashtags: #chatGPT #ExplainableAI #BooleanLogic Summery: The rapid growth of artificial intelligence (AI) and machine learning applications in various industries has raised concerns about the complexity and lack of transparency in these systems. In fields like finance and medicine, where regulations and best practices require explainability, the current black box algorithms used in AI can…

The Fidelity Center for Applied Technology (FCAT) and the Amazon Quantum Solutions Lab have collaborated to propose an interpretable machine learning model for Explainable AI (XAI) based on expressive Boolean formulas. This approach aims to address the complexity of AI algorithms and meet the transparency requirements of industries like finance and medicine. The model has been successfully implemented and benchmarked on public datasets, showing competitive performance. The use of special purpose hardware or quantum devices can further enhance the model's efficiency. This XAI model has potential applications in healthcare and finance, providing insights for product development and marketing optimization.
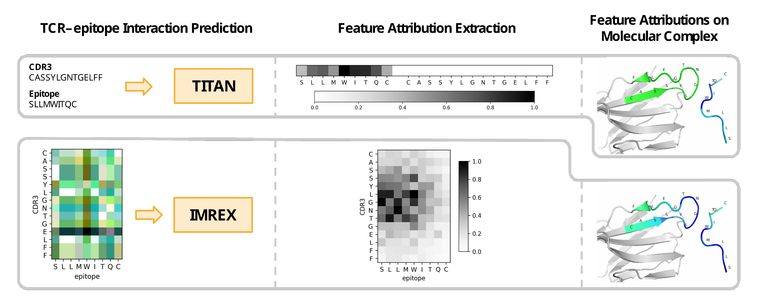
Our latest paper has now been published in #ImmunoInformatics! 🎉
Predicting #TCR #epitope binding is extremely challenging. 🤯 We used #InterpretableAI techniques to explore how these prediction models work, to achieve a deeper understanding of TCR–epitope interactions and learn how these computational tools can be improved. 🕵️
Publication: https://www.sciencedirect.com/science/article/pii/S2667119023000071
Interpretable AI really wants to understand what neurons in LLMs are doing. But this effort is very likely to fail – and it's not the right approach to understand what AI is doing and why.
Like, today, there's weirdly a lot of press about how OpenAI just showed that "Language models can explain neurons in language models" (https://openai.com/research/language-models-can-explain-neurons-in-language-models). But look at the metrics – this was a failed effort. GPT-4 *cannot explain* what neurons in GPT-2 are doing.
More importantly, single-unit interpretability in LLMs is not the same as understanding why and what LLMs as a whole are doing. Even if you did understand when a handful of units activate, you will never be able to stitch these together into a general understanding of why an LLM says the words that it does.
LLMs may someday be able to explain themselves in plain language. But describing (in plain language) when each neuron fires is not going to get us there.
“Why is it that neurons sometimes align with features and sometimes don't? Why do some models and tasks have many of these clean neurons, while they're vanishingly rare in others?
In this paper, we use toy models — small ReLU networks trained on synthetic data with sparse input features — to investigate how and when models represent more features than they have dimensions.“


