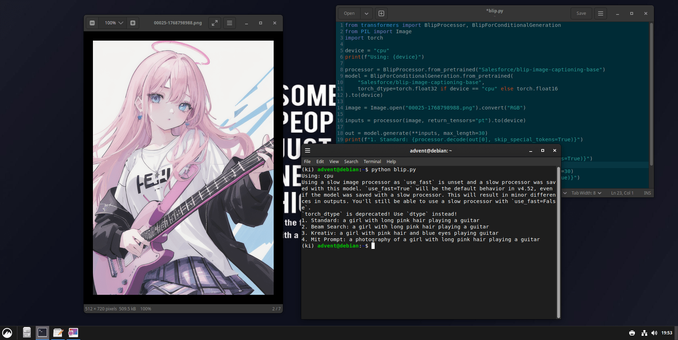
FOSS Advent Calendar - Door 21: See What AI Sees with BLIP
Meet BLIP, the versatile open source AI that bridges vision and language. It's not just another image recognition tool, it's a unified model that can understand images and generate human-like text about them, performing tasks like visual question answering, image captioning, and even searching images based on natural language queries.
Its strength lies in its multifaceted design. Trained on web-scale image-text pairs, BLIP excels at both understanding the content of an image and generating accurate, nuanced descriptions. This makes it incredibly useful for creating accessible alt-text, organizing large photo libraries with intelligent search, or building interactive applications where AI can "see" and "talk" about visual content. Everything runs locally, keeping your visual data private.
Whether you're automating metadata generation, building an educational tool, or adding smart visual analysis to your project, BLIP provides a powerful, all-in-one solution to make your applications see and describe the world.
Pro tip: Use BLIP to automatically caption your image datasets, or combine it with a TTS model like Coqui to create a system that describes images out loud.
Link:
https://github.com/salesforce/BLIP
How will you give your projects better vision? Automating alt-text, creating a visual Q&A chatbot, or organizing a decade of unsorted photos?
#FOSS #OpenSource #BLIP #ComputerVision #AI #Accessibility #AltText #ImageCaptioning #VQA #VisionAndLanguage #LocalAI #DeepLearning #MultimodalAI #Fediverse #TechNerds #AdventCalendar #adventkalender #adventskalender #KI #FOSSAdvent #Adventskalender #ArtificialIntelligence #KünstlicheIntelligenz