🚨 NEWS: Crawl Budget: come ottimizzare la scansione di Googlebot sul tuo sito
Ecco i punti chiave in breve:
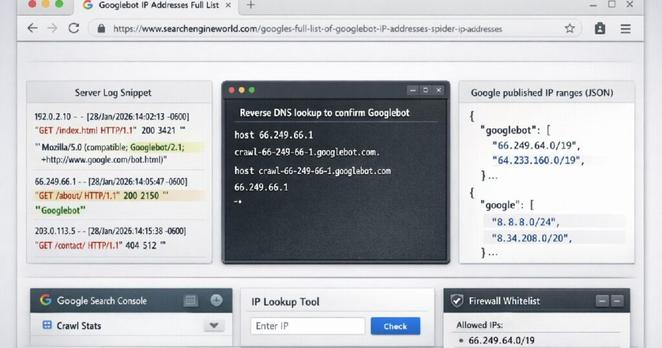
💡 Il tuo sito ha 10.000 pagine, ma Google ne indicizza solo 500. Hai contenuti di qualità, ma nessuno li trova. Non è un errore di contenuto: è un problema di crawl budget. Googlebot non scansiona...
#googleSearchConsole #sitemapXML #crawlBudget #googlebot #ottimizzazioneScansione