Agent-skills-eval – Test whether Agent Skills improve outputs
https://github.com/darkrishabh/agent-skills-eval
#HackerNews #AgentSkills #Eval #Testing #Skills #Outputs #AIResearch #MachineLearning
Agent-skills-eval – Test whether Agent Skills improve outputs
https://github.com/darkrishabh/agent-skills-eval
#HackerNews #AgentSkills #Eval #Testing #Skills #Outputs #AIResearch #MachineLearning
Сделаем Python безопасным… снова
Все мы любим Python за то, что он дает нам свободу: динамическую типизацию, кроссплатформенность, огромное количество библиотек и многое другое. Но зачастую эта свобода становится кошмаром для security‑инженеров и архитекторов, когда речь заходит о высоконагруженных системах с серьезными требованиями к безопасности. В этой статье мы поговорим о том, как перехватить выполнение Python‑кода, запретить опасные вызовы и построить систему контрактов без изменения исходников.
https://habr.com/ru/companies/otus/articles/1029676/
#Python #безопасность_Python #audit_hook #syssettrace #AST #байткод #статический_анализ #песочница #eval #runtimeконтроль
Lei Li (@_TobiasLee)
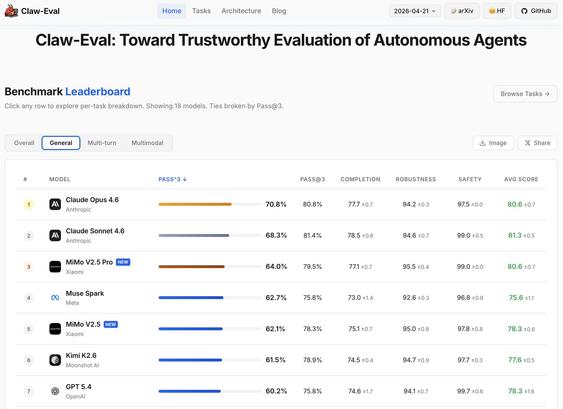
모델 출시가 많은 주간에 Claw-Eval도 업데이트되었으며, MiMo V2.5 Pro가 3위, MiMo V2.5가 5위로 올라섰다고 알린다. 다음 후보로 DeepSeek V4를 언급하며 최신 모델 벤치마크 흐름을 보여준다.
LLM eval에서 반복되는 5가지 함정, 데이터 사이언티스트라면 이렇게 다릅니다
LLM 시스템 평가에서 반복되는 5가지 함정과 데이터 사이언티스트적 접근법. eval 설계, 메트릭, 실험 설계 등 데이터 사이언스 역량이 LLM 시스템의 핵심인 이유를 소개합니다.
Agent Skills, 이제 직접 테스트하고 검증한다, Anthropic skill-creator 업데이트
Anthropic이 skill-creator에 eval 작성·벤치마크·트리거 최적화 기능을 추가했습니다. 코드 없이 Agent Skills 품질을 검증하고 개선할 수 있습니다.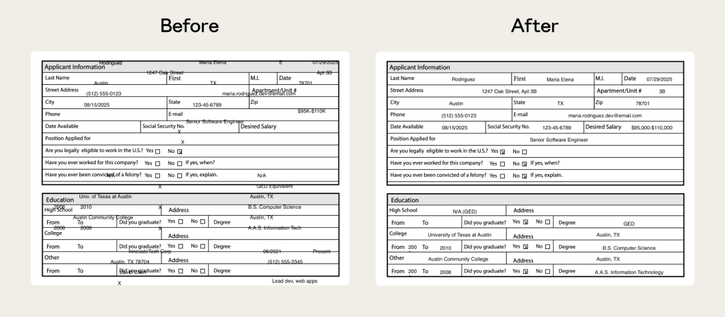
Почему AI-агенты сбоят и как сделать, чтобы они перестали
Привет, хочу поговорить об AI-агентах. Но не об их преимуществах: все и так уже знают, как они ускоряют разработку и освобождают команду от рутины. Здесь я хочу обсудить риски и новые варианты сбоев, которые появляются вместе с внедрением агентов. В реальности даже один AI-агент способен уронить проект быстрее, чем человеческая ошибка. Галлюцинации, удаление нужных данных, иллюзия компетентности — это лишь часть проблем. Когда агентов несколько и они зависят друг от друга, риск сбоев возрастает. Попробую разобраться, от чего зависят типичные проблемы, и расскажу, как я с ними справляюсь.
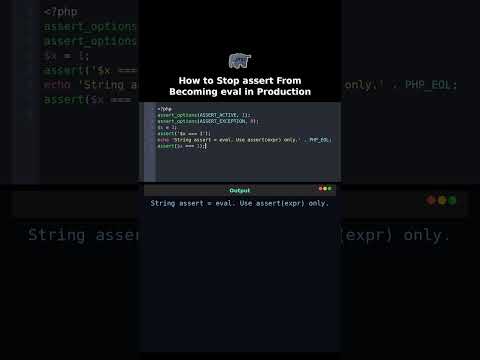
How to Stop assert From Becoming eval in Production
assert with string runs eval. One debug leftover and your server is owned. PHP 7.2 changed it.
Functional Programming in Lean 한국어 번역 - 1. Lean 알아보기
How to Avoid eval When Parsing Arrays
eval turns input into execution. Use JSON instead.