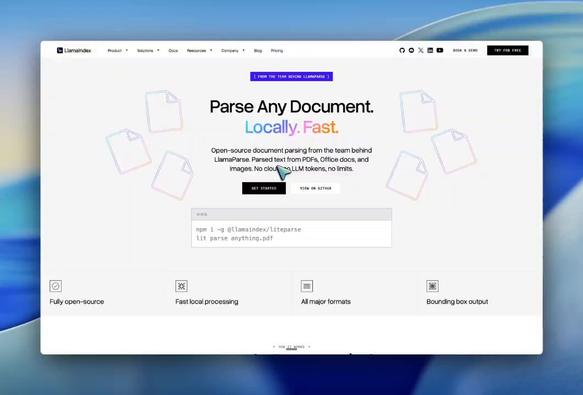
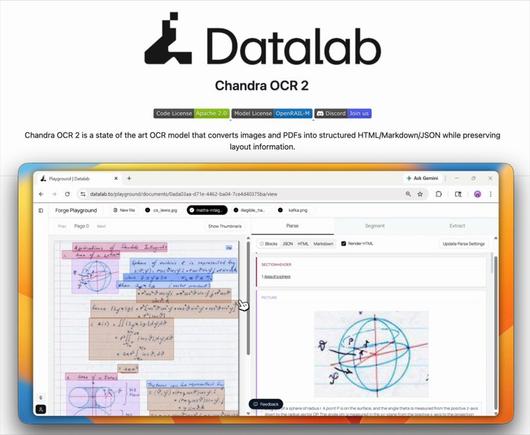
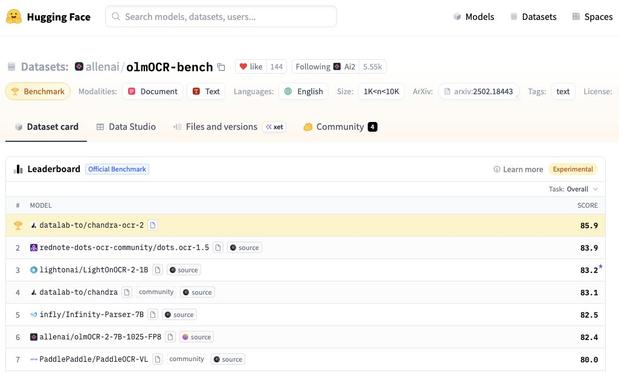
KI-gestützte Angebotsvorbereitung und Dokumentenanalyse werden aus meiner Sicht in vielen technischen Branchen stark unterschätzt. Gerade bei Ausschreibungen, Leistungsverzeichnissen und umfangreichen Dokumentationen kann strukturierte KI-Unterstützung viel Zeit sparen.
#DocumentAI #KI #Ausschreibung #Automation #BusinessAI
#DocumentAI #KI #Ausschreibung #Automation #BusinessAI