AISatoshi (@AiXsatoshi)
클라우드에 업로드할 수 없는 문서를 대상으로 근접 독해와 동료 교정을 지원하는 앱을 만들고, Dense 모델을 활용해 독해 해상도를 점검하는 작업을 진행했다.
AISatoshi (@AiXsatoshi)
클라우드에 업로드할 수 없는 문서를 대상으로 근접 독해와 동료 교정을 지원하는 앱을 만들고, Dense 모델을 활용해 독해 해상도를 점검하는 작업을 진행했다.
Abhishek Yadav (@abhishek__AI)
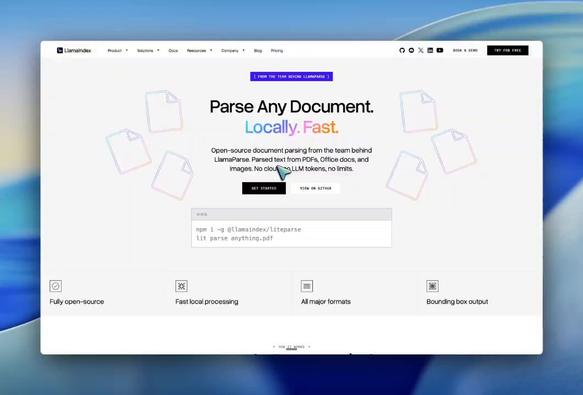
LiteParse는 클라우드 의존성 없이 동작하는 가벼운 오픈소스 PDF 파서로, 내장 OCR, JSON/Text 출력, 이미지·문서·PDF 처리, LLM용 스크린샷 생성, 바운딩 박스 기반 공간 텍스트 추출을 지원합니다. 문서 파싱과 멀티모달 입력 처리에 유용한 신규 도구입니다.
AISatoshi (@AiXsatoshi)
NVIDIA의 Nemotron OCR v2가 소개됐다. 이미지 내 문자 위치를 찾고, 텍스트를 읽어 문자열로 변환하며, 레이아웃과 읽기 순서까지 이해한다. 여러 줄 문서, 다중 블록 레이아웃, 간판·풍경 속 문자 등 복잡한 실제 OCR 환경에 대응하는 모델이다.
SB Intuitions (@sbintuitions)
문서 이미지 분석에 특화된 OCR 모델 Sarashina2.2-OCR가 공개되었으며, 레이아웃 보존, Markdown 변환, 일본어 세로쓰기 문서 지원, 표·그림 검출 기능을 제공한다.
MiniMax (official) (@MiniMax_AI)
사무용 에이전트 개발을 위한 오픈소스 스킬을 공개했다. PDF, Excel, PPT, Word 등 문서 작업에 활용할 수 있는 기능으로, AI 에이전트의 업무 자동화와 문서 처리 역량을 높이는 데 유용한 도구로 보인다.
Akshay (@akshay_pachaar)
새로운 OCR 모델이 공개되었으며, olmocr 벤치마크에서 85.9% SOTA를 달성했습니다. 90개 이상의 언어를 지원하고, 모델 크기는 9B에서 4B로 줄었지만 레이아웃 정보, 이미지·도표 캡션 추출, 필기/수식/폼/표 인식 성능이 강합니다. 100% 오픈소스입니다.
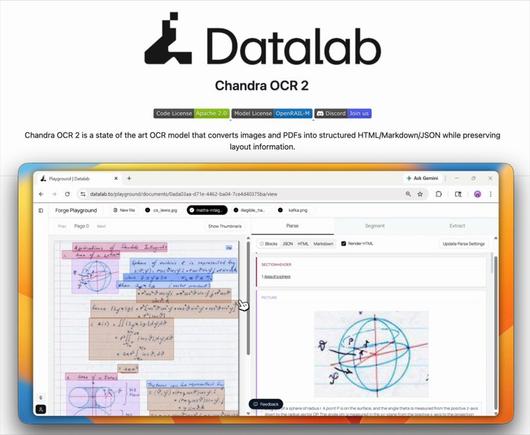
Everyone is sleeping on this new OCR model! - 85.9% (sota) on olmocr bench - 90+ language support w/benchmarks - 4B model (down from 9B) - Full layout information - Extracts + captions images and diagrams - Strong handwriting, math, form, table support 100% open-source.
Nathan (@nathanhabib1011)
@VikParuchuri 팀이 신규 OCR 모델 Chandra OCR 2를 공개했다. olmocr 벤치마크 1위(85.9%)를 기록했고, 90개 이상 언어 지원, 40억 파라미터 규모, 레이아웃 정보 추출, 이미지·도표 캡션 생성, 필기·수식·양식 인식 강화 등 문서 이해 기능이 크게 향상됐다.
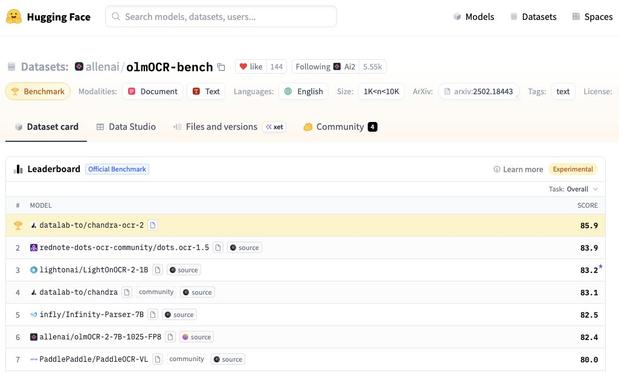
NEW SOTA OCR MODEL DROPPED Congrats to @VikParuchuri and team for releasing Chandra OCR 2! - 85.9% on olmocr bench, making it first place 🏆 - 90+ language support - 4B model - Full layout information - Extracts + captions images and diagrams - Strong handwriting, math, form,
Baidu Inc. (@Baidu_Inc)
Qianfan-OCR가 공개되었습니다. 문서 지능을 위한 4B 파라미터 엔드투엔드 모델로, 단일 패스로 표 추출, 수식 인식, 차트 이해, 핵심 정보 추출을 모두 수행합니다. 파이프라인 없이 문서 처리 작업을 통합한 점이 핵심입니다.

🚀 Introducing Qianfan-OCR: a 4B-parameter end-to-end model for document intelligence. One model. No pipeline. Table extraction, formula recognition, chart understanding, and key information extraction, all in a single pass. Paper: https://t.co/cmNhv5SLgV Models:
merve (@mervenoyann)
비전-언어 모델(VLM) 관련 서적에 새로 두 장이 추가되었다는 공지입니다. 문서 AI 장은 기존 모델부터 최신 VLM 접근법, 검색(retrieval) 등을 정리하고, 비디오 언어 모델 장은 비디오 이해와 관련 기법 및 실무 노하우를 다룹니다. 발표자가 직접 집필한 문서 AI 장도 포함되어 있습니다.

two more chapters on vision language models book is out! > document AI chapter (by yours truly) shows old models, new VLM approaches, retrieval and more! > video language models chapter shows video understanding, know-hows, approaches and more! sneak peek below
Aryan Rakib (@tec_aryan)
바이두가 문서 AI 분야의 진전을 알리며 PaddleOCR-VL-1.5를 오픈소스로 공개했습니다. 9억 파라미터급 모델로 OmniDocBench V1.5에서 전 세계 1위(94.5% 정확도)를 달성, 기존 모델들을 제치며 문서 인식용 멀티모달 OCR의 중요한 개선을 보여줍니다.

@Baidu_Inc open-sourced PaddleOCR-VL-1.5, marking an exciting advancement in document AI. 🚀 This open-source OCR model contains just 0.9 billion parameters and ranks #1 globally on OmniDocBench V1.5 with an impressive 94.5% overall accuracy, surpassing models like