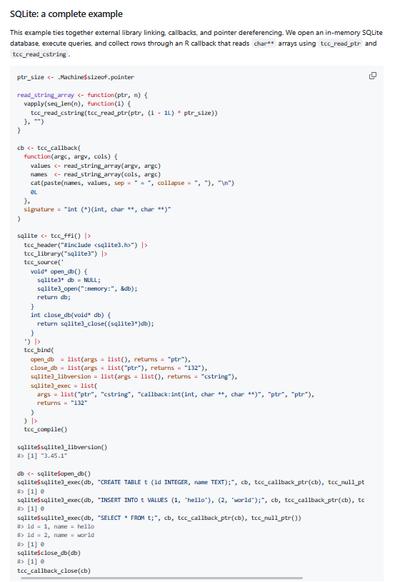
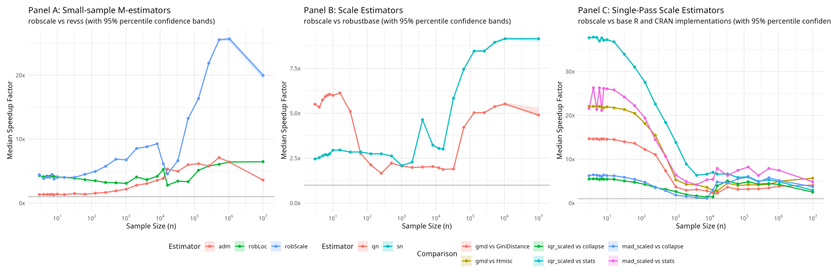
robscale 0.5.3 is now on CRAN: A major update since the last public release (0.2.1).
New: 11 robust estimators with confidence intervals, plus a variance-weighted ensemble combining seven scale statistics via bootstrap. Newton–Raphson replaces scoring iteration (2–4 steps vs 6–8), a fused AVX2 kernel does NR accumulation in one data pass, and all input validation runs in C++ with zero R-side allocation.
Speedups vs existing implementations:
Small samples (n ≤ 20):
• robScale/robLoc: 4–5× vs revss 3.1.0
• Qn: 6× vs robustbase
• MAD: 21–26× vs stats::mad
• IQR: 37× vs stats::IQR
Mid-to-large samples (n ≥ 1000):
• robScale: 2–4× vs revss
• Sn: 7–9× vs robustbase
• MAD: 5–8× vs stats::mad
• IQR: 5–7× vs stats::IQR
• GMD: 2–8× vs GiniDistance
https://cran.r-project.org/package=robscale
https://github.com/davdittrich/robscale
#RStats #Statistics #RobustStatistics #CRAN #DataScience #OpenSource