Some cool work from allen institute where they trained a more understandable mixture of experts model. The content that the experts are experts at are more clustered and better resemble human topics. A big benefit of this is it looks like you can remove an expert from the model and performance degrades much more gracefully than a standard MoE.

I did some experiments to compare AI2's tools Asta and DR-Tulu. Reports A and B
have the exact same prompt and Report A from Asta is superior in quality.
Reports C and D have the same prompt and Report D is better and more relevant to the query as DR-Tulu has superior iterative reasoning abilities compared to Asta.
Report A:
https://asta.allen.ai/share/cba36194-fdf3-475d-b7b7-bf8da8ca8095
Report B:
https://www.dr-tulu.org/shared/2MlHrP4OGZ2D
Report C:
https://asta.allen.ai/share/0d362688-c278-4b19-9187-f44be594a50a
#Ai2 has released #MolmoWeb, an #openweight #visualwebagent that operates from browser screenshots and executes actions like clicking, typing, and scrolling. It comes with #MolmoWebMix, a dataset of 30,000 human task trajectories and 2.2 million screenshot question-answer pairs, making it the largest publicly released collection of human web-task execution. https://venturebeat.com/data/ai2-releases-molmoweb-an-open-weight-visual-web-agent-with-30k-human-task?eicker.news #tech #media #news
Wes Roth (@WesRoth)
마이크로소프트가 전 Ai2 CEO Ali Farhadi를 Corporate Vice President로 영입했고, 그와 함께 우수 AI 연구팀도 합류해 새롭게 재편된 AI 조직을 강화한다고 밝혔다. 연구 역량 확대와 조직 개편 측면에서 중요한 인사다.

Wes Roth (@WesRoth) on X
Microsoft has hired Ali Farhadi, the former CEO of the Allen Institute for Artificial Intelligence (Ai2), as its new Corporate Vice President. He is bringing a team of elite AI researchers with him to bolster Microsoft's newly restructured AI division. Farhadi recently stepped
Microsoft Hires Former Ai2 CEO Farhadi for Suleyman AI Team
#Microsoft #AI #MustafaSuleyman #Copilot #BigTech #AITalentWar #Superintelligence #AIResearch #MachineLearning #AITalent #AIModels #AliFarhadi #AI2 #HannaHajishirzi

merve (@mervenoyann)
AI2(Allen Institute for AI)가 포인팅(pointing) 작업에서 SOTA 성능을 목표로 한 새로운 비전 언어 모델 패밀리 'MolmoPoint'를 공개함. 공개된 모델은 MolmoPoint-8B(범용), MolmoPoint-GUI-8B(그래픽 UI용), MolmoPoint-Vid-4B(비디오 내 계수/추적)이며, 관련 데이터셋도 함께 제공됨.

Ai2: Building physical AI with virtual simulation data https://www.artificialintelligence-news.com/news/ai2-building-physical-ai-with-virtual-simulation-data/ #ai2 #physicalai #molmobot #opensource #robotics #ai #technology

merve (@mervenoyann)
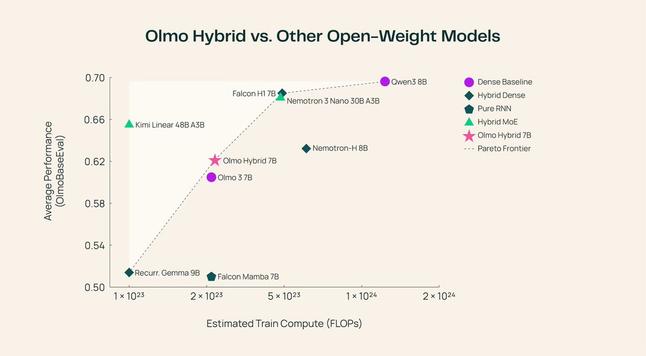
Allen Institute for AI(AI2)가 Olmo Hybrid 모델군(base/SFT/DPO)을 공개했습니다. 이 모델군은 트랜스포머와 RNN 레이어를 혼합해 FLOP 대비 학습 효율이 높은 구조를 추구하며 학습 측면에서 파레토 프런티어에 위치한다고 주장하고 확장성도 확보했다고 보고했습니다. 또한 학습 데이터 믹스도 함께 공개되었습니다.
Ai2’s open coding agents slash costs for developers https://www.developer-tech.com/news/ai2s-open-coding-agents-slash-costs-for-developers/ #ai2 #opensource #developers #ai #devtools #coding #agenticai #technology

Tim Dettmers (@Tim_Dettmers)
Ai2의 Open Coding Agent 시리즈 첫 모델 SERA 출시 발표. 작성자는 SERA가 동일 규모에서 SoTA 성능을 보이고 설계가 단순하며, 강화학습(RL) 대비 26배 효율적이라고 주장함. 상세 설명과 개발 여정은 Tim Dettmers의 블로그 글로 제공.

Tim Dettmers (@Tim_Dettmers) on X
We release SERA, the first model part of Ai2’s Open Coding Agent series. SERA is a SoTA agent for its size, super simple, and 26x more efficient than RL. In my blog post, I write about my personal journey of building this coding agent: https://t.co/kPZHUGwBBC Details: 👇