


zaicurity
- 38 Followers
- 222 Following
- 1.1K Posts
He/Him, Currently clean on OPSEC, Infosec, Shitposting
Got Nessus? Got Crowdstrike? You might also have a huge pile of false positives this morning, as Nessus attempted to run a PoC of the "MiniPlasma" exploit proactively, triggering CrowdStrike alerts.
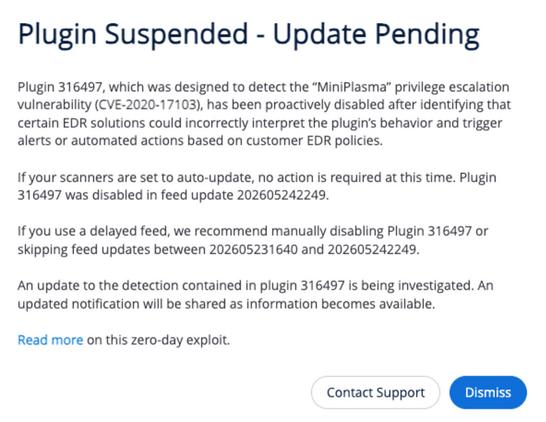
CrowdStrike/S1 triggering 1000s of High Severity Alerts on Tenable (2026-05-25)
For some wild reason, Tenable decided to run a recent PoC as part of their vulnerability scanning, generating thousands of alerts across customer EDRs this last Memorial Day weekend. CrowdStrike Support Notice (Login required) https://supportportal.crowdstrike.com/s/article/Tech-Alert-US-1-US-2-EU-1-MiniPlasma-Detection-2026-05-25
Well done to Epic Games, who tweeted and then deleted, when called out, this GenAI image of their Porsche partnership.
Butchers the Porsche logo, puts Riot Games logo on the balloon (a competitor) and other things.

The pressure
for us in the #curl project right now

The pressure
I'm doing Open Source primarily because I love it. The social aspects, the for-the-good angle and for the challenge of engineering this to work for everyone. I also do it because it is my full-time job and getting food on the table and provide for my family is not unimportant. It may come as a … Continue reading The pressure →

For they were, all of them, deceived.
For the Dark Lord Sauron had embedded deep within his EULA the right to change the terms and conditions without notice
And once the users had become dependent on the service
He started increasing the cost of his tokens
For the Dark Lord Sauron had embedded deep within his EULA the right to change the terms and conditions without notice
And once the users had become dependent on the service
He started increasing the cost of his tokens
 .
.RE: https://hachyderm.io/@inthehands/116619120828325229
I have a whole host of concerns with LLMs, and I'm mostly of the same mind as this person. Resource-wise, its a massive waste. Ethically, the companies producing the datasets said that intellectual property theft was fine, so long as they were the ones doing it.
but my biggest concern is that, as a cybersecurity professional, for a lot of the "vibe coding" models, they are pulling in data from github, reddit, and stack exchange over the past decade or so, maybe even longer than that.
While all of those sources over the years have been somewhat nice (if a little bit elitist) for learning programming concepts, there are A LOT of incomplete and incorrect answers out there. Or things that work on paper, but we then discovered through YEARS of CVEs that they aren't the most secure or best method for doing the thing(tm).
LLMs make no distinction about that. The training set, is the training set. There's no context that says this is "technically correct, but if you do this in prod, that is really fucking dumb idea." Even so, companies fucking RAN WITH IT. Like it was THE golden calf. Sacrificed their workforces, sacrificed lives, bought out ALL of the RAM, and ALL of the SSDs, only for the models to be wholly inadequate, or in the case of mythos, and the other new models, a nothingburger.
I am waiting with bated breath for the rug pull when these companies stop subsidizing the cost of compute, so that all of the assholes who dropped their workforce will have to eat massive piles of shit.
I've said in the past that we missed our chance for the tech industry to unionize in the 90s. The second best time would be when the shit hits the fan on LLM pricing.
The models aren't going to get any better. They're running out of data to feed to the machine.
Everyone is fighting the installation of datacenters in their backyard and rightly so because they are a MASSIVE problem, with very little reutrn.
The infra noise is harmful, the community ends up having to foot the massive power bill, the water supply ends up noticeably worse, and in many cases, they supplement with gas turbines causing the air quality to suffer as well.
The leaders of these companies are all shitheads who are willfully sticking their heads into the sand, because its in interest of their financial survival to do so, and to continue with the smoke and mirrors.
Fuck AI, and fuck those who support it.